Te hablé de la teoría. Te expliqué por qué los prompts son mi nueva forma de computación, cómo oculto la basura técnica de las herramientas y por qué un LLM sin arquitectura es solo un loro glorificado.
Hoy se acabo tanto concepto. Nos vamos a ensuciar las manos.
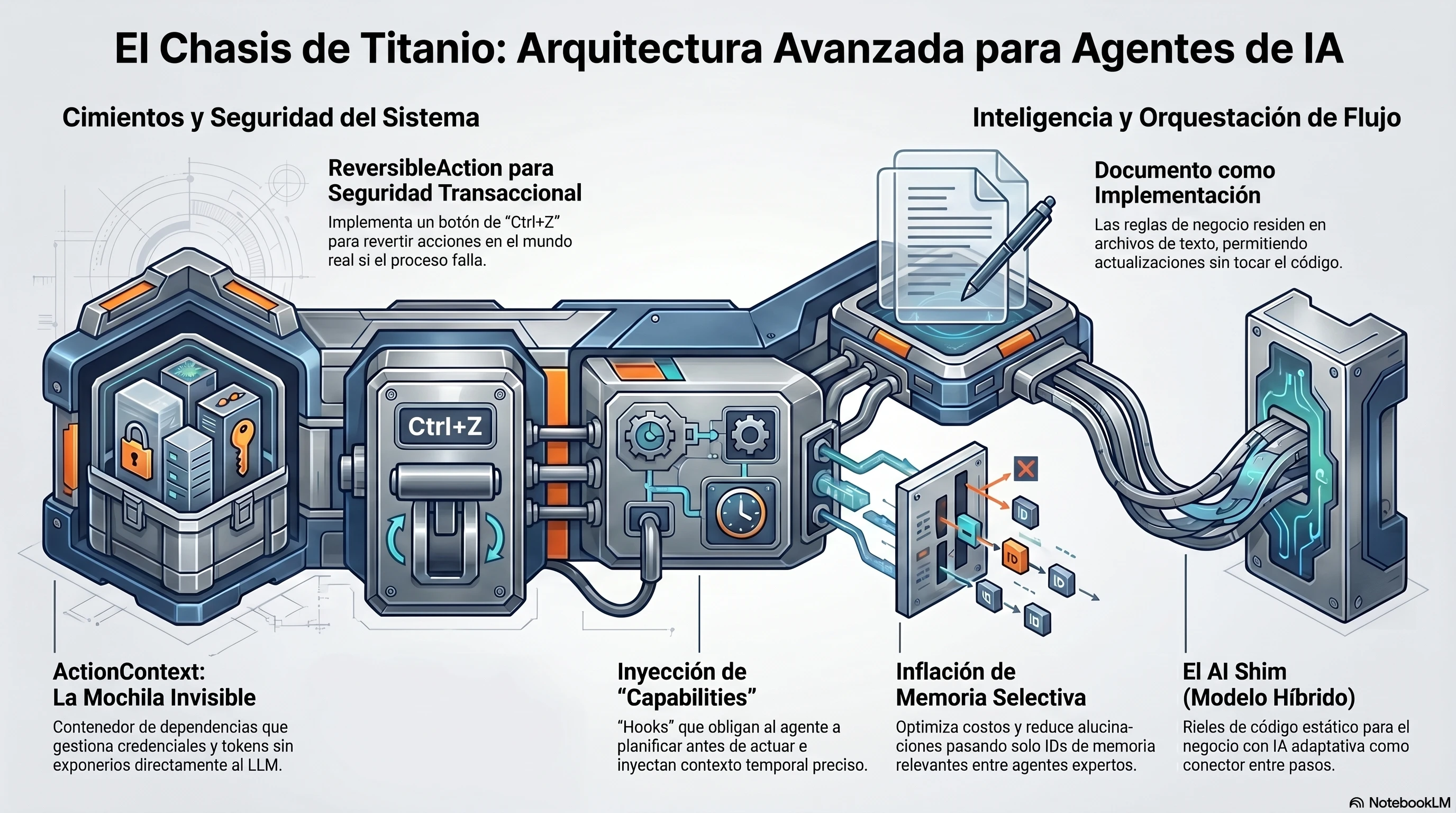
Voy a mostrarte cómo construyo el chasis para mis agentes integrando absolutamente todos los patrones avanzados de los que hemos hablado: desde Inyección de Dependencias hasta Memoria Multi-Agente, Seguridad Transaccional y Documento como Implementación.
Vamos a programar el núcleo de un Sistema Financiero Multi-Agente. Un Coordinador que planea, extrae datos, delega con contexto inteligente y audita usando políticas humanas.
Mira el código. No es magia, es ingeniería. 😊
Para este caso práctico, lo desgloso en seis pasos claros y directos cada concepto que vimos en el post anterior, transformando la teoría en un ejemplo real de gran impacto para tus desarrollos.
Paso 1: Setup del Entorno con UV
La velocidad importa. Yo no uso gestores de paquetes lentos. Uso uv porque es brutalmente rápido y me permite inicializar proyectos en segundos. Instalo lo básico: los SDKs de OpenAI/Anthropic y Pydantic para cuando necesitemos esquemas JSON ultra-estrictos.
uv init agente_financiero
cd agente_financiero
uv add openai anthropic pydantic python-dotenv
El archivo .env es mi primera línea de defensa. Mis agentes jamás tendrán credenciales hardcodeadas en sus prompts. Ese ERP_SECRET_TOKEN es la llave de mi castillo financiero; en el siguiente paso verás cómo hago que las herramientas lo usen sin que el agente central siquiera sepa que existe.
Paso 2: El Chasis (ActionContext) y la Seguridad (Transacciones)
No permito que el agente maneje tokens de seguridad ni que deje bases de datos rotas si falla. Empiezo con mi contenedor de dependencias (ActionContext) y mi red de seguridad ambiental (Principios MATE).
import uuid
# 1. EL CONTENEDOR DE DEPENDENCIAS (Inyección Limpia)
class ActionContext:
def __init__(self, properties=None):
self.context_id = str(uuid.uuid4())
self.properties = properties or {}
def get(self, key: str, default=None):
return self.properties.get(key, default)
# 2. SEGURIDAD AMBIENTAL (Transacciones y Rollbacks)
class ReversibleAction:
def __init__(self, execute_func, reverse_func):
self.execute = execute_func
self.reverse = reverse_func
self.history = None
def run(self, **kwargs):
self.history = self.execute(**kwargs)
return self.history
def undo(self):
if self.history:
self.reverse(**self.history)
# Si el agente guarda un gasto, pero el envío de email falla, borro el gasto automáticamente. No hay estados inconsistentes.
Qué está pasando aquí: Mira el ActionContext. Piénsalo como una mochila invisible que viaja por todo mi sistema. Yo meto las contraseñas, los tokens y las zonas horarias en esa mochila. Las herramientas pueden meter la mano y sacar lo que necesitan, pero el agente (el LLM) tiene los ojos vendados. Solo se enfoca en razonar.
Luego está ReversibleAction. Este es mi seguro de vida. Es mi botón de "Ctrl+Z" para el mundo real. Si mi agente reserva un vuelo, pero luego la tarjeta de crédito falla al reservar el hotel, yo no dejo la reserva del vuelo colgada. Ejecuto undo() y revierto el primer paso usando el historial que guardé. Cero estados inconsistentes. O el proceso se hace perfecto, o no se hace.
Paso 3: El Cerebro (Planificación) y el Entorno (Pasante del Día 1)
Un agente es como un pasante en su primer día: no sabe qué hora es, ni tiene un plan a menos que lo obligues. Uso el patrón Capability para hackear el ciclo de vida del agente sin ensuciar su código central.
class Capability:
def process_prompt(self, action_context, messages): return messages
def init(self, agent, action_context): pass
# 1. INYECTANDO EL MUNDO REAL (TimeAwareCapability)
class TimeAwareCapability(Capability):
def process_prompt(self, action_context, messages):
# El agente siempre sabrá qué hora es antes de tomar decisiones
timezone = action_context.get("time_zone", "America/Chicago")
messages.insert(0, {"role": "system", "content": f"ESTADO DEL MUNDO: Hoy es 2024-10-25. Zona: {timezone}"})
return messages
# 2. OBLIGANDO A PENSAR (PlanFirstCapability - Ahead-of-Time Planning)
class PlanFirstCapability(Capability):
def init(self, agent, action_context):
# Antes de actuar, el agente genera un plan numerado y lo guarda en su memoria
plan = "PLAN:\n1. Extraer datos.\n2. Delegar a auditor.\n3. Guardar en DB."
action_context.properties["memory"].append({"id": "mem_0", "content": plan})
Esto es ingeniería pura aplicándose sobre el LLM. En lugar de crear un prompt espagueti gigantesco, uso "Hooks" (ganchos) para interceptar el proceso.
En TimeAwareCapability, intercepto los mensajes milisegundos antes de que salgan hacia OpenAI o Anthropic (process_prompt). Le inyecto la hora y fecha exacta. El agente se despierta sabiendo exactamente en qué momento del tiempo vive.
En PlanFirstCapability, intervengo en el inicio absoluto del sistema (init). Obligo al agente a escribir un plan paso a paso y lo clavo en su memoria (mem_0). Así, cuando el bucle lleve 10 iteraciones, el agente no perderá el norte porque su plan sigue grabado en piedra.
Paso 4: Las Herramientas (JSON, In-Context Learning y Documento como Implementación)
Aquí separo a los profesionales de los novatos. Voy a crear herramientas que obligan al LLM a trabajar como una CPU de verdad. Y fíjate en el parámetro _erp_token: mi Entorno lo inyecta, pero lo oculta del agente.
import json
# 1. EXTRACCIÓN ESTRUCTURADA + IN-CONTEXT LEARNING (Few-Shot)
def extract_expense_data(text: str) -> str:
""" Extrae datos usando JSON y enseñando con ejemplos, no con reglas """
prompt = f"""
Extrae los datos. Sigue este patrón estricto:
Ejemplo 1:
Problema: "Comí una hamburguesa por 15 USD"
Pensamiento: Es comida rápida.
JSON: {{"monto": 15, "concepto": "hamburguesa"}}
Ahora hazlo para: {text}
"""
# Ejecución simulada de prompt_llm_for_json
return json.dumps({"monto": 160.00, "concepto": "Cena cliente"})
# 2. DOCUMENTO COMO IMPLEMENTACIÓN + INYECCIÓN DE DEPENDENCIAS
def audit_against_policy(action_context: ActionContext, data_json: str, _erp_token: str) -> str:
""" Lee políticas humanas y audita. El _erp_token fue inyectado en secreto. """
if not _erp_token: raise ValueError("Fallo de seguridad: ERP Token ausente.")
# El texto .txt es mi lógica de negocio. Cero 'if/else' duros.
with open("politica_viajes.txt", "r") as f:
policy = f.read()
datos = json.loads(data_json)
# Aquí el LLM usaría el texto de la política para razonar:
if datos["monto"] > 150:
return f"RECHAZADO según política. ERP (Token {_erp_token[:4]}...) no tocado."
return "APROBADO. Transacción guardada."
Mira bien extract_expense_data. En lugar de darle 50 reglas sobre cómo leer un recibo, aplico In-Context Learning (Few-Shot). Le doy ejemplos claros de "Problema -> Pensamiento -> JSON". El LLM es una máquina de completar patrones; al ver el ejemplo, me devolverá un JSON impecable sin chistar.
Ahora mira audit_against_policy. Este es el Santo Grial: el Documento como Implementación. El código no tiene la regla "límite = 150". El código simplemente abre el archivo politica_viajes.txt. Si Recursos Humanos cambia la política mañana a 200 USD, solo editan el .txt. Mi sistema se actualiza sin que yo escriba una sola línea de código nuevo. Además, fíjate en el guion bajo de _erp_token. Esa es mi señal para el sistema: "inyecciónala desde la mochila (ActionContext), pero escóndesela al LLM".
Paso 5: Multi-Agente y el Truco de los IDs (Memory Inflation)
Si mi Agente Coordinador le pasa TODO el historial al Agente Auditor, desperdicio tokens y provoco alucinaciones. Uso la Delegación con Memoria Selectiva.
def call_agent_auditor(action_context: ActionContext, task: str) -> str:
# 1. EL TRUCO DE LOS IDs
# El coordinador analiza la memoria y me pasa un JSON solo con los IDs relevantes
memoria_actual = action_context.get("memory")
llm_decision = {"selected_memories": ["mem_0", "mem_2"]}
# "Inflo" la memoria: busco el texto real de esos IDs
memoria_filtrada = [m for m in memoria_actual if m["id"] in llm_decision["selected_memories"]]
# 2. EL PATRÓN DE PERSONA
# Instancio al especialista dinámicamente
persona_prompt = "Actúa como un Auditor Senior implacable. Revisa estos datos."
# 3. MESSAGE PASSING (Paso el mensaje y espero el resultado)
print(f"[AUDITOR EXPERTO ACTIVADO]: Evaluando tarea '{task}' con contexto filtrado.")
# El Auditor llama a la herramienta 'audit_against_policy' internamente
resultado = audit_against_policy(action_context, task, action_context.get("erp_token"))
return resultado
Este es el truco de la Inflación de Memoria. Cuando llamo a un agente experto, no le digo al coordinador "hazme un resumen de todo". Le digo: "dame los IDs de la memoria que importan".
El LLM solo gasta un par de tokens en decirme ["mem_0", "mem_2"]. Luego, mi código Python hace el trabajo pesado: busca esos IDs en la mochila, extrae los textos largos originales y los inyecta (los "infla") en el prompt del nuevo agente experto. Ahorro dinero, mantengo el texto original intacto (cero alucinaciones) y activo al nuevo agente usando el Patrón Persona ("Actúa como un Auditor Senior"). Es una cadena de montaje perfecta.
Paso 6: Ejecución (El AI Shim)
Ensamblamos el motor. El modelo que uses (Claude 3.5 o GPT-5) es irrelevante, porque la arquitectura soporta el peso. Yo defino el flujo de negocio estático, y la IA actúa como un AI Shim (un adaptador inteligente) entre los pasos.
import os
def run_agent(user_input: str):
print(">>> INICIANDO SISTEMA MULTI-AGENTE DE ÉLITE <<<\n")
# 1. Preparo mi Inyección de Dependencias
context = ActionContext({
"time_zone": "Europe/Madrid",
"erp_token": "TOKEN_SECRETO_ERP_99X",
"memory": [{"id": "mem_0", "content": "Usuario inicia sesión."}]
})
# 2. Hooks de Ciclo de Vida (Capabilities)
time_cap = TimeAwareCapability()
plan_cap = PlanFirstCapability()
plan_cap.init(None, context)
mensajes = [{"role": "user", "content": user_input}]
mensajes = time_cap.process_prompt(context, mensajes)
print(f"Memoria tras Capability de Planificación: {context.get('memory')[-1]['content']}\n")
# 3. El AI Shim en acción (Orquestación del flujo)
print("1. [COORDINADOR]: Ejecutando In-Context Learning para extracción...")
datos_limpios = extract_expense_data(user_input)
context.get("memory").append({"id": "mem_2", "content": datos_limpios})
print(f"Datos: {datos_limpios}\n")
print("2. [COORDINADOR]: Delegando. Inflando Memoria por IDs e invocando Persona...")
# Self-Prompting: El agente se llama a sí mismo en otro rol
resultado_auditoria = call_agent_auditor(action_context=context, task=datos_limpios)
print(f"\n>>> [RESULTADO FINAL]: {resultado_auditoria}")
if __name__ == "__main__":
queja_empleado = "Ayer pagué 160 dólares por una cena con el cliente principal. Reembolso urgente."
run_agent(queja_empleado)
Este es mi orquestador principal. Aquí es donde se ejecuta el Modelo Híbrido o AI Shim. Fíjate que no le he dado al LLM un bucle infinito while True para que decida qué hacer y cruzo los dedos para que acierte.
Yo controlo el flujo del negocio:
Extraer datos.
Delegar y auditar.
Es estático. Es seguro. Pero uso la inteligencia del LLM entre esos pasos. La IA extrae los datos caóticos y los convierte en JSON. Luego, otro agente de IA usa esos datos precisos para evaluar una política en lenguaje natural. Yo pongo los rieles del tren, la IA es la locomotora.
Al ejecutar esto en tu consola, verás cómo todo cobra vida. Cero basura técnica en los prompts, contexto preciso y una ejecución predecible que respeta las reglas de tu empresa. Eso es ingeniería.
Un Detalle de Arquitecto: ¿Por qué no usé un Bucle Infinito?
Si prestaste atención al código del Paso 6, seguro notaste el elefante en la habitación: no hay un bucle while True. El agente no está decidiendo de forma autónoma cuándo llamar a la herramienta A y cuándo a la B.
Te hablo claro: esto no fue un olvido, fue una decisión de diseño de nivel corporativo.
Aplicamos exactamente lo que te enseñé en la teoría: el AI Shim (Modelo Híbrido). Para un proceso crítico como auditar gastos, no quiero que el agente improvise. Yo sé que el proceso es estricto: 1) Extraer datos, 2) Auditar. Si suelto al agente en un bucle adaptativo puro, corro el riesgo de que alucine, pierda el tiempo, gaste tokens extra o ejecute los pasos al revés.
Yo pongo los rieles del tren (el flujo de Python), y uso la inteligencia de la IA solo como un adaptador perfecto entre las estaciones. Es el modelo más rápido, barato y seguro para producción.
¿Mi arquitectura (ActionContext, Capabilities) soporta un bucle autónomo? Por supuesto. El chasis de titanio está diseñado para aguantar lo que le tires.
De hecho, en el próximo artículo, vamos a quitar los frenos. Usaremos esta misma arquitectura exacta, pero implementaremos la Ejecución Totalmente Adaptativa (el famoso bucle del agente) para un caso de uso exploratorio donde el flujo no se conoce de antemano. Prepárate, porque vamos a soltar a la bestia.
Conclusión del Caso Práctico
Si ejecutas esto, verás la sinfonía en acción.
El sistema planifica antes de actuar. Inyecta la hora real. Extrae datos usando ejemplos. Filtra la memoria por IDs para no saturar al especialista. El especialista asume un Rol de Persona, lee un archivo de texto humano (Documento como Implementación) y rechaza el gasto. Todo mientras el token del ERP permanece inyectado por el entorno, 100% invisible para el agente, y respaldado por lógica transaccional.
Construir agentes inteligentes no se trata de apilar prompts larguísimos y esperar un milagro. El Gran Dilema de elegir entre un flujo totalmente dinámico (caótico) o un workflow rígido (tonto) lo resuelvo con el AI Shim: yo controlo el negocio, la IA aporta el razonamiento.
Al usar ActionContext aislas el ruido técnico. Al usar Capabilities controlas el ciclo de vida. Al usar la arquitectura correcta, dejas de jugar con chatbots y empiezas a construir software autónomo de impacto real.
El chasis de titanio está listo. Ahora, constrúyelo.
#AIArchitecture #AgenticAI #MultiAgentSystems #Python #GenerativeAI #SoftwareEngineering