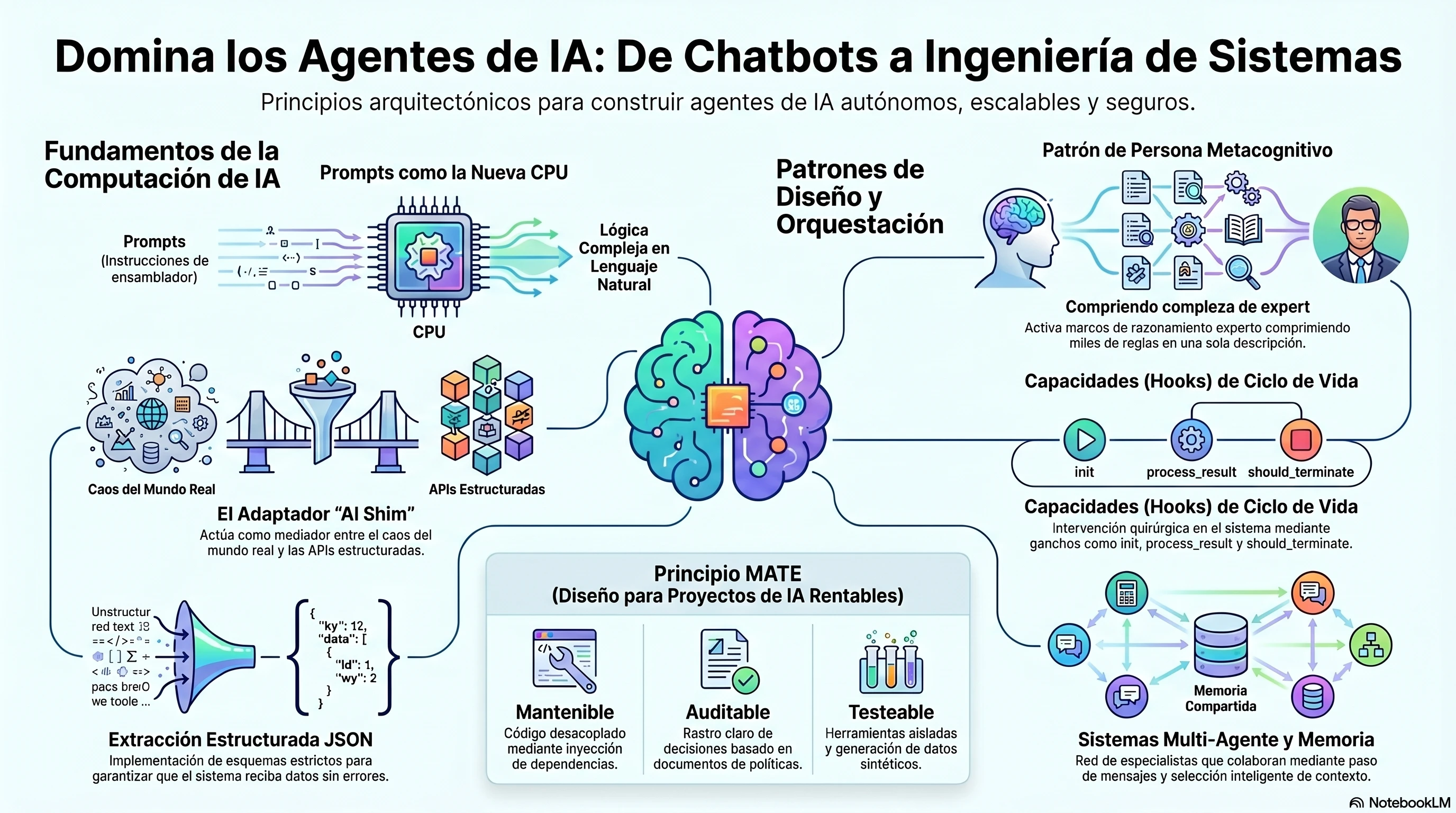
Mira la IA generativa y los prompts de una forma distinta: no son solo herramientas, son mi nueva forma de computación. Los veo como los bloques de construcción fundamentales que uso para dar vida a agentes autónomos avanzados. No es ciencia ficción, es ingeniería de impacto.
Para que esto funcione de verdad, aplico el Patrón de Persona. Es una técnica brutalmente poderosa que domino para activar marcos de razonamiento especializados. No me conformo con respuestas genéricas; hago que la IA simule expertos o sistemas modulares mediante descripciones quirúrgicas.
En mi arquitectura, la colaboración multi-agente es el motor del proyecto. He perfeccionado métodos de comunicación como el paso de mensajes y la memoria compartida, seleccionando el contexto de forma inteligente. ¿El resultado? Un procesamiento de información superior que no desperdicia ni un solo token.
Lo que más me enorgullece es el concepto de Documento como Implementación. He logrado que las políticas humanas, escritas en lenguaje natural, se conviertan directamente en la lógica operativa de mis sistemas. Es eficiencia pura.
Al final, todo se resume en cómo ejecuto. Equilibro la flexibilidad con el control total, contrastando procesos dinámicos y predeterminados para asegurar que el sistema sea tan predecible como potente.
📚 Índice del post
La Nueva Frontera: IA Generativa como mi Nueva CPU.
Prompts como Computación: Por qué un prompt es una operación lógica.
El Puente (AI Shim): Conectando el caos del mundo real con mis APIs rígidas.
Extracción Estructurada: El arte de obligar al LLM a hablar en JSON.
Escalabilidad Horizontal y Self-Prompting: El agente que habla consigo mismo.
Limpieza Extrema: Inyección de Dependencias y el Entorno.
El Patrón Capability: Hackeando el ciclo de vida del agente.
El Patrón de Persona: Activando marcos de razonamiento expertos.
Documento como Implementación: Políticas humanas como lógica de negocio.
Darle Contexto al Agente: El "Pasante del Día 1".
In-Context Learning: Educar sin reglas.
Principios de Diseño MATE y Seguridad Ambiental.
Sistemas Multi-Agente: Delegación, comunicación y memoria compartida.
Planificación y Razonamiento: De planes "Ahead-of-Time" a reflexión "In-Loop".
El Gran Dilema: Dinámico vs. Predefinido.
Conclusión.
Empecemos:
1. La Nueva Frontera: IA Generativa como mi Nueva CPU
He dejado de ver a la inteligencia artificial generativa como un simple "chat" curioso. Para mí, es mucho más: es una nueva forma de computación. Si quieres construir agentes que realmente muevan la aguja, tienes que dejar de pensar en "trucos de magia" y empezar a ver los prompts como bloques de construcción fundamentales, casi como instrucciones de ensamblador para una CPU de lenguaje natural.
En este artículo te voy a mostrar cómo diseño sistemas donde la IA no solo responde preguntas, sino que ejecuta lógica compleja. He pasado de programar flujos rígidos a orquestar inteligencia, y los resultados son, sencillamente, superiores. Olvida lo que sabías sobre software tradicional; aquí es donde el lenguaje se convierte en motor.
2. Prompts como Computación: Más allá del Texto
Cuando escribo un prompt, no estoy "pidiendo un favor" a la máquina. Estoy ejecutando una operación lógica. Para un desarrollador de élite, un prompt es una unidad de procesamiento que puede realizar tareas que antes requerían cientos de líneas de código Python.
¿Quieres una prueba de este impacto real? Mira este ejemplo. Si necesito simular un entorno de archivos para probar mi sistema, no pierdo el tiempo programando generadores de strings complejos. Uso la capacidad computacional del LLM para crear datos sintéticos con una precisión asombrosa.
Ejemplo de Implementación: Generación de Entorno
# No estoy "chateando", estoy definiendo una función de generación de datos
prompt_computacional = """
Genera una lista JSON de 10 archivos simulados en un directorio /downloads/.
Cada objeto debe tener: 'filename', 'extension', 'size_mb' y 'last_modified'.
Asegúrate de que los nombres parezcan reales (ej. 'factura_abril.pdf', 'foto_vacaciones.jpg').
"""
# El LLM actúa como mi motor de ejecución de datos
resultado = agente.ejecutar(prompt_computacional)
Por qué esto es superior:
Velocidad: He construido una herramienta de testeo en segundos, no en horas.
Flexibilidad: Si mañana necesito que los archivos sean logs de servidor en lugar de descargas, solo cambio la "instrucción de cómputo".
Poder: El sistema "entiende" el contexto de lo que es un archivo realista, algo que un generador aleatorio tradicional jamás lograría con tanta naturalidad. También uso esto para "Organización semántica": le paso una lista de archivos y le pido que cree un árbol de directorios separando "trabajo" de "personal". Intenta programar eso en Python clásico... buena suerte. 😁
3. El Puente (AI Shim): Conectando el Caos con la Estructura
En el mundo real, la información es un desastre: correos mal redactados, fotos de recibos borrosas o notas de voz. Por otro lado, mis APIs son rígidas y no perdonan ni una coma. Para solucionar esto, uso un concepto que llamo AI Shim (o adaptador de IA).
Actúo como un mediador: tomo ese contenido analógico y "sucio" del mundo real y lo proceso para que encaje perfectamente en mis sistemas tradicionales. No dejo que el agente invente el flujo; yo defino el camino y uso la IA para "rellenar los huecos" entre cada paso técnico.
Mientras que un workflow puramente dinámico le da libertad total al agente (lo cual es riesgoso en procesos de negocio), el AI Shim actúa como una 'calza' en un proceso estático (Paso A -> Paso B). El agente no inventa el camino, pero asegura que los datos fluyan y se adapten perfectamente. Es la combinación perfecta entre previsibilidad corporativa y flexibilidad de IA.
4. Extracción Estructurada: El Arte del JSON Perfecto
Extraer datos no es adivinar; es transformar. He diseñado una herramienta robusta, prompt_llm_for_json, que obliga al modelo a entregarme exactamente lo que necesito para mis bases de datos. No acepto texto libre cuando lo que busco es precisión.
Para lograr esto, utilizo Esquemas JSON. Le doy al agente el molde exacto y le prohíbo salirse de él.
Ejemplo Técnico: Mi Extractor de Facturas de Élite 😂
Imagina que recibo un texto desordenado de una factura. En lugar de procesarlo a mano, ejecuto este bloque lógico:
# Defino el esquema: mi contrato de datos
invoice_schema = {
"type": "object",
"required": ["invoice_number", "total_amount"],
"properties": {
"invoice_number": {"type": "string"},
"vendor": {"type": "string"},
"total_amount": {"type": "number"},
"items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"desc": {"type": "string"},
"price": {"type": "number"}
}
}
}
}
}
# Ejecución: convierto el caos en una estructura impecable
data = prompt_llm_for_json(
schema=invoice_schema,
prompt="Extrae los datos de esta factura: 'Factura No. A-45, Total 500 USD de Amazon...'"
)
Cero fallos de formato: Implemento una lógica de reintentos en prompt_llm_for_json (hasta 3 veces) que busca los bloques ```json para asegurar que el JSON sea válido antes de que mi sistema lo toque. Esta tecnica tiene algunos puntos importantes:
Validación estricta: Si faltan campos obligatorios como el número de factura, el sistema lo detecta de inmediato.
Escalabilidad: No importa si el proveedor cambia el diseño de su PDF; mi "CPU de IA" entiende el contexto y extrae la información sin que yo tenga que reprogramar nada.
Hablemos un poco de Escalabilidad Horizontal y Self-Prompting: El Agente que Habla Consigo Mismo es un error de novato es inflar el prompt central del agente con miles de instrucciones, intentando que sepa hacer de todo. Yo no hago eso. Yo aplico la Escalabilidad Horizontal a través de Herramientas. Mantengo el "cerebro" del agente limpio y enfocado en coordinar, y expongo prompts especializados como herramientas individuales. Esto habilita mi movimiento más inteligente: el Self-Prompting. Mi agente principal no tiene que ser un experto en todo; lo que hace es consultarse a sí mismo usando herramientas especializadas. Es como un CEO que, cuando necesita un análisis legal, no intenta hacerlo él mismo, sino que llama a su "departamento legal".
@register_tool(tags=["document_processing", "invoices"])
def extract_invoice_data(action_context: ActionContext, document_text: str) -> dict:
"""Extrae datos usando un esquema fijo y un prompt especializado."""
extraction_prompt = f"""
Eres un experto analista de facturas. Extrae la información con precisión.
Presta atención a:
- Números de factura (busca 'Invoice #', 'No.', 'Referencia')
- Fechas (fecha de emisión)
- Montos totales
Piensa paso a paso. Texto del documento:
{document_text}
"""
return prompt_llm_for_json(
action_context=action_context,
schema=invoice_schema,
prompt=extraction_prompt
)
Esto me permite aislar la complejidad. Si quiero mejorar la extracción, modifico esta herramienta, no toco las metas del agente central.
6. Limpieza Extrema: Inyección de Dependencias y el Entorno
Para los desarrolladores expertos, el patrón ActionContext es vital. Permite la inyección de dependencias, desacoplando las herramientas de la complejidad técnica del agente.
Supongamos que una herramienta necesita actualizar una base de datos o un sistema externo y requiere un auth_token. Bajo ninguna circunstancia dejo que el agente se entere de que ese token existe. Si el agente tuviera que manejar tokens o IDs de sesión, su razonamiento se contaminaría (y sería un desastre de seguridad). Yo delego esa inyección a mi Environment (Entorno).
El entorno inspecciona la firma de la función de la herramienta. Si ve un parámetro que empieza con _(como_auth_token), sabe que es privado. Va al ActionContext, saca el token y se lo inyecta a la herramienta en tiempo de ejecución.
El golpe maestro: Oculto estos parámetros del Esquema JSON que lee el agente.
def get_tool_metadata(func, ...):
signature = inspect.signature(func)
args_schema = {"type": "object", "properties": {}, "required": []}
for param_name, param in signature.parameters.items():
# SALTO los parámetros técnicos. El agente NO debe verlos.
if param_name in ["action_context", "action_agent"] or param_name.startswith("_"):
continue
# Agrego solo los parámetros reales de negocio al esquema
args_schema["properties"][param_name] = {"type": "string"}
return {"parameters": args_schema, ...}
Así, el agente ve una herramienta que pide "nombre de usuario" y "nuevo estado". Su razonamiento es puro y enfocado en el negocio. Toda la basura técnica, las conexiones a la base de datos y la seguridad, las inyecto yo por detrás.
7. El Patrón Capability: Hackeando el Ciclo de Vida
No todo en mi sistema es una herramienta que el agente decide llamar. He implementado un patrón: las Capacidades (Capabilities). A diferencia de las herramientas, las capacidades me permiten intervenir en momentos exactos del bucle del agente mediante "hooks" o ganchos de ciclo de vida. Es como tener sensores y actuadores en el sistema nervioso del agente.
init: Configuro estados al iniciar.
process_prompt: Modifico el mensaje justo antes de enviarlo al LLM.
process_result: Transformo el resultado de una herramienta antes de que el agente lo vea.
should_terminate: Tomo el control total para decidir cuándo detener al agente y evitar bucles infinitos.
Mira cómo implemento una Capacidad de Conciencia Temporal. No es una herramienta que el agente elige llamar; es un "middleware" que se ejecuta automáticamente.
class TimeAwareCapability(Capability):
def init(self, agent, action_context):
# Establece la hora al inicio de la ejecución en la memoria del sistema
timezone = action_context.get("time_zone", "America/Chicago")
current_time = datetime.now(ZoneInfo(timezone))
action_context.get_memory().add_memory({
"type": "system",
"content": f"El tiempo actual es {current_time.strftime('%H:%M %A, %B %d, %Y')}."
})
def process_prompt(self, agent, action_context, prompt):
# Hook: Inyecta la hora exacta en cada mensaje enviado al LLM
timezone = action_context.get("time_zone", "America/Chicago")
current_time = datetime.now(ZoneInfo(timezone))
system_msg = f"Hora actual: {current_time.strftime('%H:%M')} ({timezone})\n\n"
# El agente siempre sabe qué hora es antes de procesar cualquier cosa
prompt.messages.insert(0, {"role": "system", "content": system_msg})
return prompt
No es magia, es ingeniería. Integrado mediante la función reduce de Python, esto me permite encadenar capacidades en un pipeline de inteligencia pura sin tocar el código central del agente.
8. El Patrón de Persona: Activando Expertos en un Clic
Para mí, el Patrón de Persona es una de las abstracciones de programación más potentes y eficientes que existen. No se trata solo de decirle a la IA "sé amable"; se trata de activar un marco de razonamiento complejo que ya está integrado en el modelo.
Cuando le digo al sistema: "Actúa como un auditor senior de ciberseguridad financiera", estoy comprimiendo miles de reglas, metodologías y prioridades en una sola frase. Es brutalmente eficiente en el uso de tokens porque no tengo que explicarle qué es un riesgo o cómo reportar una vulnerabilidad.
En mi arquitectura, llevo las personas al límite:
Metacognición (Role-Switching): Hago que el agente cambie deliberadamente de rol. Primero revisa el problema como un experto en seguridad, luego como uno en UX, y luego como un optimizador de rendimiento. Esto contrarresta los sesgos cognitivos propios de un solo enfoque.
Expertos Dinámicos: Tengo expertos predefinidos, pero también permito que mi sistema genere personas al vuelo. Si mi agente enfrenta un problema inédito, le pido que escriba la descripción perfecta del especialista necesario, genere el prompt, y luego asuma ese rol para resolverlo.
Experiencia como Documentación: Mis definiciones de personas son tan detalladas que sirven como documentación viva. Un nuevo desarrollador lee la persona "Ingeniero QA Senior" y sabe exactamente cuáles son las capacidades del sistema.
9. Documento como Implementación: Políticas Humanas como Lógica de Negocio
Este es el punto donde rompo con el pasado y elimino la "Pérdida por Traducción".
Tradicionalmente, las reglas de negocio mueren en el camino: un experto dicta una política, un desarrollador la interpreta y luego la escribe en código rígido (ej. if gasto > 500). En cada paso, se pierden matices vitales.
Con el patrón de Documento como Implementación, mi agente lee directamente el documento humano (un PDF o un .txt) y lo usa como su motor lógico.
@register_tool()
def check_purchasing_rules(action_context: ActionContext, invoice_data: dict):
# El documento original (.txt o PDF) es mi código lógico
try:
with open("config/purchasing_rules.txt", "r") as f:
purchasing_rules = f.read()
except FileNotFoundError:
purchasing_rules = "No hay reglas definidas. Proceder con precaución."
# Paso la política "cruda" al experto. Él decide basándose en el texto real.
return prompt_expert(
action_context=action_context,
description_of_expert="Oficial de cumplimiento de adquisiciones.",
prompt=f"Datos factura: {invoice_data}. Reglas actuales: {purchasing_rules}. ¿Cumple?"
)
Por qué esto cambia el juego:
Actualizaciones dinámicas: Si mi empresa actualiza sus políticas de reembolsos mañana, solo cambio el archivo de texto en el disco. Mi sistema se adapta al instante sin que yo tenga que tocar una sola línea de código o hacer un nuevo despliegue.
Transparencia total: Cuando el agente toma una decisión, crea un rastro auditable conectado exactamente al párrafo vigente del manual de la empresa.
10. Darle Contexto al Agente: El "Pasante del Día 1"
Uno de los mayores errores al construir IA agentica es sobrestimar lo que el LLM sabe sobre tu mundo.
Imagina a un pasante brillante que llega a tu oficina el día 1. Conoce el mundo en general, pero no sabe dónde está la cafetera, ni cómo funciona tu sistema interno, ni qué proveedores prefieres.
Si le digo a un agente "prende la TV", va a fallar. No sabe si mi TV está colgada en la pared, qué cables tiene conectados, ni qué puertos están libres. Necesito inyectarle información constante sobre el estado del mundo. Le paso fotos, logs actuales y estructuras de datos antes de que ejecute. Si no actualizas su entendimiento del entorno tras cada acción, tomará decisiones catastróficas basadas en datos desactualizados.
11. In-Context Learning: Educar sin Reglas
Explicarle a un agente cómo interactuar con un sistema de la vieja escuela usando solo reglas puede ser una pesadilla. Los sistemas computacionales tradicionales son frágiles, no aceptan formatos extraños.
¿Cómo lo resuelvo? Con In-Context Learning (Few-Shot Prompting). Le enseño con ejemplos, exactamente igual que haría con un humano.
Imagina que tengo herramientas con IDs incomprensibles (X155, Q63) y no quiero escribir largos manuales. Le muestro el patrón:
Problema: Siento hambre.
Pensamiento: Necesito preparar comida.
Herramienta: Q63
Resultado: Pizza alienígena preparada.
Problema: Necesito moverme a otro mundo.
Pensamiento: Necesito un agujero de gusano.
Herramienta: X155
Resultado: Agujero de gusano abierto.
Si luego le digo al agente: "Problema: Necesito escapar de esta nave a la Tierra", el agente (queriendo completar el patrón) dirá: "Pensamiento: Necesito localizar una vía de escape. Herramienta: X155".
Le enseñé a razonar y usar herramientas complejas (como sumar tiempo en un microondas o interactuar con APIs rígidas) simplemente mostrándole el camino. Es una técnica vital para limitar alucinaciones y forzar salidas predecibles.
12. Principios de Diseño MATE y Seguridad Ambiental
No construyo agentes a ciegas. Sigo los principios MATE, que son mi seguro de vida para que los proyectos sean rentables y seguros:
Sigla | Concepto | Mi Enfoque |
|---|---|---|
M | Model efficiency | Uso el modelo más barato y rápido que pueda cumplir la tarea. No gasto una "Reina" (GPT-4/Gemini Ultra) para mover un "Peón" (extraer un nombre de un texto). |
A | Action specificity | Diseño herramientas concretas. Es mejor tener un botón de "Reprogramar reunión" que uno genérico de "Modificar calendario" que el agente pueda romper fácilmente. |
T | Token efficiency | Cada token cuesta dinero y tiempo. Mantengo mis prompts densos en información y libres de basura para que la ejecución sea rápida y económica. |
E | Environmental safety | El agente opera en un entorno seguro. Prefiero acciones que se puedan deshacer (reversibles) y que no causen un desastre si la IA comete un error. |
Seguridad de Grado Transaccional
Cuando mis agentes operan en el mundo real, no los dejo "sueltos" se deben basar en lo siguientes conceptos:
Acciones Reversibles: Mis herramientas registran lo necesario para "deshacerse" a sí mismas.
Gestión de Transacciones: Agrupo acciones atómicas. Si el agente reserva un vuelo pero falla en el hotel, ejecuto un rollback automático. O todo sale perfecto, o no se hace nada. No permito estados inconsistentes.
# Gestiono la transacción como una unidad atómica
transaction = ActionTransaction()
transaction.add(create_event, title="Daily Sync con el equipo")
try:
await transaction.execute()
transaction.commit() # Si todo sale bien, se confirma
except Exception:
await transaction.rollback() # Si falla, borra el evento automáticamente
Ejecución Etapada (Staged Execution): Para alto riesgo (mover dinero, correos masivos), el agente genera el plan, pero las acciones quedan "en pausa". Un humano u otra IA las revisa y aprueba antes de la ejecución real.
Herramienta Única Segura vs. Múltiples Riesgosas
No caigas en la trampa de dar 10 herramientas diminutas al agente y rezar para que las orqueste bien. Yo construyo la Herramienta Única Segura.
@register_tool(description="Agendar reunión de equipo de forma segura")
def schedule_meeting_safely(action_context, title, attendees, duration):
# Validaciones, chequeo de disponibilidad y envío de notificaciones
# TODO encapsulado en código inmutable. El agente NO puede saltarse pasos.
if len(attendees) > 10:
raise ValueError("Límite de seguridad: Máximo 10 asistentes")
...
13. Sistemas Multi-Agente: Delegación y Memoria Inteligente
He aprendido que los agentes funcionan mejor cuando son especialistas. En lugar de un solo agente gigante, construyo una red de expertos. Un Agente Coordinador (Project Manager) usa una herramienta call_agent para delegar tareas a especialistas (ej. un "scheduler_agent").
¿Cómo se hablan mis agentes? Uso tres patrones según el caso:
Message Passing: El coordinador envía una tarea y recibe solo el resultado final. Limpio y eficiente.
Memory Reflection: El especialista devuelve el resultado y su proceso de pensamiento (los pasos intermedios). Así el coordinador aprende el "por qué".
Memory Handoff: Le paso el contexto completo al siguiente agente para que tome el relevo de una tarea compleja.
El Truco de los IDs de Memoria (Inflation)
Aquí hay un problema grave: el historial crece, pero los LLMs tienen un límite de tokens de salida. Si intento que el agente asigne contexto resumiendo todo, voy a sufrir alucinaciones y perder tokens valiosos.
Mi solución es la Selección Inteligente de Contexto. A cada mensaje en la memoria le asigno un ID corto (mem_1, mem_2).
# 1. Asignación de IDs temporales a la memoria
memory_with_ids = [{"id": f"mem_{i}", "content": m["content"]} for i, m in enumerate(memory.items)]
# 2. El LLM (Self-Prompting) analiza y elige solo los IDs relevantes para la nueva tarea
selected_ids = set(llm_response["selected_memories"])
# 3. El código "infla" los contenidos literales para el siguiente agente
filtered_memory = [m for m in memory_with_ids if m["id"] in selected_ids]
El agente solo me gasta tokens de salida escupiendo un JSON con ["mem_1", "mem_4"]. Mi código toma esos IDs, busca el texto literal original y lo "infla" en el prompt del siguiente agente. Cero alucinaciones, precisión absoluta y eficiencia extrema. Esto habilita mi Cadena de Expertos, una línea de producción donde un QA valida literalmente el código de un Dev sin perder contexto.
14. Planificación y Razonamiento: El Cerebro del Agente
No puedo esperar que la IA resuelva un problema complejo de un solo golpe. Necesita "tiempo para pensar".
Ahead-of-Time Planning (PlanFirstCapability): Antes de tocar cualquier herramienta de ejecución, obligo al agente a detenerse, crear un plan estructurado, numerado y detallado, y guardarlo en su memoria principal. Puedo usar un modelo caro (GPT-5 o Claude Opues 4.7) solo para crear el plan, y uno barato (GPT-3.5/Claude Haiku) para ejecutarlo paso a paso.
In-Loop Planning (Seguimiento): Si la tarea es larga, el plan original quedará enterrado en el historial. Por eso uso una capacidad que, cada N iteraciones, obliga al agente a generar un "Reporte de Progreso". El agente lee lo que acaba de hacer, identifica bloqueos y define cuál es el siguiente paso lógico.
15. El Gran Dilema: Dinámico vs. Predefinido
No siempre le doy al agente el volante completo. Existen trade-offs críticos, y los manejo con tres estilos de ejecución:
Ejecución Totalmente Adaptativa (Dinámica): El agente decide cada paso en cada bucle. Es súper flexible para problemas ambiguos, pero es el más lento, costoso y propenso a desviarse.
Generación de Workflow Estático: El agente crea el plan al principio, yo lo convierto en código/flujo y lo ejecuto "fuera de la vista" de la IA. Es brutalmente rápido y barato, pero si ocurre un error a la mitad, no hay un agente para reaccionar.
El Modelo Híbrido (El AI Shim): Mi favorito para el mundo corporativo. Yo establezco el proceso inmutable (ej. Sacar datos -> Transformar -> Enviar email). La IA se inserta entre esos pasos. No decide qué hacer después, solo razona sobre cómo adaptar la salida del paso A para que sea la entrada perfecta del paso B.
16. Conclusión
He mostrado como construir una arquitectura donde la inteligencia y la ingeniería dura se dan la mano. El futuro no es simplemente "preguntar cosas a una IA en un chat". El futuro es construir sistemas que razonen, planeen, deleguen y ejecuten con la precisión y seguridad de un reloj suizo.
Si aplicas estos patrones (Capabilities, ActionContext, MATE, y Documento como Implementación), dejarás de jugar con herramientas superficiales y empezarás a construir software autónomo de impacto real.
#AIArchitecture #AgenticAI #LLMOps #SoftwareEngineering #PromptEngineering #GenerativeAI #AutonomousAgents