Te lo prometí. 😀
En el post anterior te mostré el chasis de titanio: ActionContext, Capabilities, seguridad transaccional, memoria por IDs. Y al final te dije algo importante: en ese sistema financiero, yo controlaba el flujo. Yo puse los rieles. El agente no decidía qué hacer después, solo ejecutaba lo que yo había predefinido.
Eso fue una decisión de diseño. No un límite de la arquitectura.
Hoy quitamos los frenos. Vamos a implementar la Ejecución Totalmente Adaptativa: el famoso bucle del agente donde el LLM decide en cada iteración qué herramienta llamar, qué información necesita y cuándo parar. Sin flujo predefinido. Sin rieles. Solo el agente razonando en tiempo real frente a un problema que no conoce de antemano.
El bucle adaptativo no es la forma más segura de ejecutar un agente. Es la más poderosa. Y para usarlo bien, necesitas entender exactamente qué está pasando en cada vuelta.
Vamos a construir un Agente Investigador de Datos Autónomo: le das un objetivo en lenguaje natural ("analiza la calidad de este dataset y dame un reporte de hallazgos"), y él decide solo cómo llegar ahí. Herramienta por herramienta. Iteración por iteración.
📚 Índice del post
Entorno listo: UV, dependencias y estructura del proyecto
El Gran Dilema, resuelto: cuándo soltar al agente y cuándo no
Anatomía del bucle adaptativo: qué pasa en cada iteración
Setup: el mismo chasis, nuevas herramientas
El bucle en código:
whilecon cerebroStop conditions: cómo evitar que el agente se pierda para siempre
In-Loop Planning: el agente que revisa su propio progreso
Ejecución completa: soltando la bestia
Conclusión: cuándo usar cada modo
0. Entorno listo: UV, dependencias y estructura del proyecto
Antes de correr una sola línea de código, necesitas el entorno correcto. Y yo no uso pip ni virtualenv para esto. Uso UV.
Si no lo conoces: UV es un gestor de paquetes y entornos para Python escrito en Rust. Es entre 10x y 100x más rápido que pip. Instala dependencias en segundos, no en minutos. Una vez que lo usas, no vuelves atrás.
Instalar UV
# macOS / Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
# Windows (PowerShell)
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
# Verificar instalación
uv --version
Qué está pasando aquí:
UV se instala como un binario único. No necesita Python previo instalado para funcionar él mismo puede gestionar las versiones de Python que necesites. Después de la instalación, reinicia tu terminal para que el PATH quede actualizado.
Crear el proyecto
# Crear la carpeta del proyecto e inicializar
uv init agente-investigador
cd agente-investigador
# Esto crea automáticamente:
# agente-investigador/
# ├── .python-version ← versión de Python anclada al proyecto
# ├── pyproject.toml ← manifiesto del proyecto (equivalente a package.json)
# ├── README.md
# └── main.py ← punto de entrada
Instalar las dependencias
Para este proyecto necesitas exactamente estas librerías:
# SDK oficial de Anthropic (para conectar con Claude)
uv add anthropic
# SDK oficial de OpenAI (si prefieres usar GPT-4o o GPT-4.1)
uv add openai
# Pydantic: validación y tipado de datos estricto para los esquemas JSON del agente
uv add pydantic
# python-dotenv: carga variables de entorno desde .env (para las API keys)
uv add python-dotenv
# rich: logging bonito en terminal opcional pero hace los logs del agente legibles
uv add rich
Con un solo comando si prefieres:
uv add anthropic openai pydantic python-dotenv rich
Qué está pasando aquí:
uv add hace tres cosas a la vez: instala la librería, crea el entorno virtual automáticamente en .venv/ dentro de tu proyecto, y actualiza pyproject.toml con la dependencia. No necesitas hacer uv venv ni source .venv/bin/activate por separado. UV gestiona todo eso solo.
Configurar las API Keys
Crea el archivo .env en la raíz del proyecto:
# .env - NUNCA subas este archivo a git
ANTHROPIC_API_KEY=sk-ant-api03-xxxxxxxxxxxxxxxx
OPENAI_API_KEY=sk-proj-xxxxxxxxxxxxxxxx
# Opcional: configuración del agente
AGENT_MAX_ITERATIONS=10
AGENT_TIMEZONE=America/Bogota
Y el .gitignore para proteger tus credenciales:
# .gitignore
.env
.venv/
__pycache__/
*.pyc
Nunca hardcodees una API key en el código. Ni para probar. Ni "solo por ahora". Una key expuesta en un repo público puede costarte cientos de dólares en minutos.
Estructura final del proyecto
Así debe quedar tu carpeta antes de correr el agente:
agente-investigador/
├── .env ← tus API keys (nunca a git)
├── .gitignore
├── .python-version ← anclado a Python 3.12
├── .venv/ ← entorno virtual (gestionado por UV)
├── pyproject.toml ← dependencias declaradas
├── politica_viajes.txt ← archivo de política (Documento como Implementación)
├── main.py ← punto de entrada principal
└── agente/
├── __init__.py
├── context.py ← ActionContext y Capabilities
├── herramientas.py ← todas las tools del agente
└── bucle.py ← el loop adaptativo
Verificar que todo está en orden
# Correr con UV directamente (sin activar el venv manualmente)
uv run python main.py
# O si prefieres activar el entorno primero
source .venv/bin/activate # macOS/Linux
.venv\Scripts\activate # Windows
python main.py
Qué está pasando aquí:
uv run es mi comando favorito. Ejecuta el script dentro del entorno virtual del proyecto sin que tengas que activarlo manualmente. Funciona siempre, desde cualquier directorio. Es el equivalente a npm run pero para Python.
Si ves esto al correr, el entorno está perfecto:
============================================================
🤖 AGENTE INVESTIGADOR - MODO ADAPTATIVO
============================================================
Si ves un ModuleNotFoundError, significa que corriste python main.py directamente sin UV. Usa uv run python main.py o activa el entorno primero.
1. El Gran Dilema, resuelto: cuándo soltar al agente y cuándo no
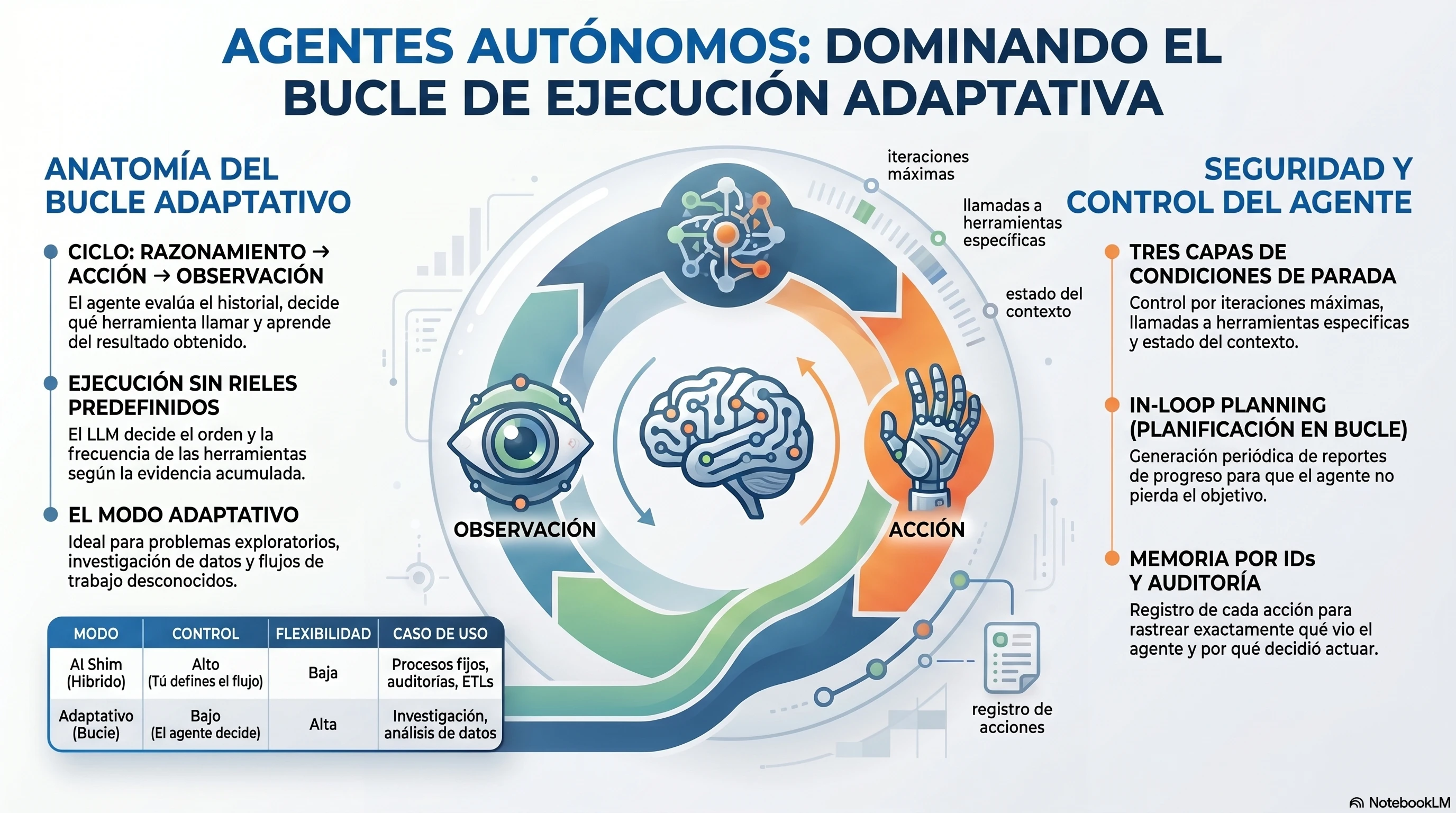
Si leíste el post anterior, recuerdas la tabla de los tres modos de ejecución. Te la refesco porque hoy la vamos a vivir en código:
Modo | Control | Flexibilidad | Costo | Cuándo usarlo |
|---|---|---|---|---|
AI Shim (Híbrido) | Tú defines el flujo | Baja | Bajo | Procesos de negocio fijos, auditorías, ETLs |
Workflow Estático | Tú defines todo | Nula | Muy bajo | Tareas repetitivas y predecibles |
Adaptativo (bucle) | El agente decide | Alta | Alto | Problemas exploratorios, investigación, flujos desconocidos |
El sistema financiero del post anterior era un AI Shim. Perfecto para producción corporativa donde el proceso no cambia.
El agente investigador de hoy es Adaptativo. Perfecto cuando le das al sistema un objetivo abierto y no sabes de antemano qué pasos necesitará para resolverlo.
La diferencia no es filosófica. Es práctica:
¿Sabes exactamente los pasos del proceso? → AI Shim.
¿El problema es exploratorio y el camino se descubre en el camino? → Adaptativo.
2. Anatomía del bucle adaptativo: qué pasa en cada iteración
Antes de escribir una línea de código, necesitas visualizar lo que va a pasar.
El bucle adaptativo funciona así en cada vuelta:
El LLM recibe el estado actual: el objetivo original + el historial de lo que ya hizo + la lista de herramientas disponibles.
El LLM decide: llama a una herramienta, o declara que terminó.
El sistema ejecuta la herramienta y guarda el resultado en la memoria.
Vuelta al paso 1. El LLM ahora tiene más contexto y decide el siguiente movimiento.
Es un ciclo de razonamiento → acción → observación → razonamiento. Igual que como tú resuelves un problema cuando no tienes el camino claro: actúas, ves qué pasa, y decides qué sigue.
El bucle adaptativo convierte al LLM en un agente que aprende del entorno en tiempo real. Cada iteración es una decisión nueva basada en evidencia acumulada.
Eso es poderoso. Y también es lo que lo hace costoso en tokens si no lo controlas bien.
3. Setup: el mismo chasis, nuevas herramientas
Reutilizamos exactamente el ActionContext y el sistema de Capabilities del post anterior. No cambio una coma de la arquitectura base. Solo agrego herramientas nuevas orientadas a análisis de datos.
import json
import uuid
import random
from typing import Any
# --- EL MISMO CHASIS DEL POST ANTERIOR ---
class ActionContext:
def __init__(self, properties=None):
self.context_id = str(uuid.uuid4())
self.properties = properties or {}
def get(self, key: str, default=None):
return self.properties.get(key, default)
def set(self, key: str, value: Any):
self.properties[key] = value
class Capability:
def process_prompt(self, action_context, messages): return messages
def init(self, agent, action_context): pass
class TimeAwareCapability(Capability):
def process_prompt(self, action_context, messages):
messages.insert(0, {
"role": "system",
"content": "CONTEXTO: Eres un agente investigador de datos. Hoy es 2025-05-07."
})
return messages
# --- HERRAMIENTAS NUEVAS PARA EL AGENTE INVESTIGADOR ---
# Simulo un dataset en memoria. En producción, esto conecta a tu base de datos real.
DATASET_SIMULADO = {
"nombre": "ventas_q1_2025",
"filas": 15420,
"columnas": ["fecha", "producto", "region", "monto", "cantidad", "vendedor_id"],
"muestra": [
{"fecha": "2025-01-15", "producto": "SKU-001", "region": "LATAM", "monto": 1200.0, "cantidad": 3, "vendedor_id": "V042"},
{"fecha": "2025-02-28", "producto": None, "region": "NA", "monto": -50.0, "cantidad": 1, "vendedor_id": "V099"},
{"fecha": "2025-03-10", "producto": "SKU-007", "region": "LATAM", "monto": 890.5, "cantidad": None, "vendedor_id": "V042"},
]
}
def inspect_dataset(action_context: ActionContext) -> str:
"""Herramienta 1: Obtiene metadata del dataset (estructura, tamaño, columnas)."""
resultado = {
"nombre": DATASET_SIMULADO["nombre"],
"total_filas": DATASET_SIMULADO["filas"],
"columnas": DATASET_SIMULADO["columnas"],
"muestra_3_filas": DATASET_SIMULADO["muestra"]
}
return json.dumps(resultado, ensure_ascii=False)
def check_nulls(action_context: ActionContext, columna: str) -> str:
"""Herramienta 2: Analiza valores nulos en una columna específica."""
# Simulo el análisis. En producción: SELECT COUNT(*) WHERE columna IS NULL
nulos_simulados = {
"producto": {"nulos": 312, "porcentaje": 2.02},
"cantidad": {"nulos": 87, "porcentaje": 0.56},
"vendedor_id": {"nulos": 0, "porcentaje": 0.0},
"monto": {"nulos": 0, "porcentaje": 0.0},
"fecha": {"nulos": 5, "porcentaje": 0.03},
"region": {"nulos": 41, "porcentaje": 0.27},
}
resultado = nulos_simulados.get(columna, {"nulos": 0, "porcentaje": 0.0})
resultado["columna"] = columna
return json.dumps(resultado)
def check_anomalies(action_context: ActionContext, columna: str) -> str:
"""Herramienta 3: Detecta valores anómalos (negativos, outliers) en una columna numérica."""
anomalias_simuladas = {
"monto": {
"negativos": 23,
"ceros": 7,
"outliers_extremos": 4,
"rango": {"min": -150.0, "max": 98500.0},
"media": 1340.22
},
"cantidad": {
"negativos": 0,
"ceros": 12,
"outliers_extremos": 8,
"rango": {"min": 0, "max": 4500},
"media": 5.3
}
}
resultado = anomalias_simuladas.get(columna, {"mensaje": f"No hay datos de anomalías para '{columna}'"})
resultado["columna"] = columna
return json.dumps(resultado)
def generate_report(action_context: ActionContext, hallazgos: str) -> str:
"""Herramienta 4: Genera el reporte final estructurado con los hallazgos del agente."""
reporte = {
"reporte_id": str(uuid.uuid4())[:8].upper(),
"dataset": DATASET_SIMULADO["nombre"],
"estado": "COMPLETADO",
"hallazgos_registrados": hallazgos,
"timestamp": "2025-05-07T14:32:00Z"
}
action_context.set("reporte_final", reporte)
return json.dumps(reporte, ensure_ascii=False)
# Registro de herramientas disponibles para el agente
HERRAMIENTAS_DISPONIBLES = {
"inspect_dataset": inspect_dataset,
"check_nulls": check_nulls,
"check_anomalies": check_anomalies,
"generate_report": generate_report,
}
Qué está pasando aquí:
Fíjate que las cuatro herramientas tienen firmas limpias: reciben el ActionContext y parámetros simples. El agente no sabe cómo funciona el dataset internamente, solo sabe que estas herramientas existen y qué hacen según su nombre y docstring.
Ese es el contrato. El agente razona sobre los nombres y las descripciones. Yo controlo la implementación real.
4. El bucle en código: while con cerebro
Aquí está la pieza que no existía en el post anterior. El bucle adaptativo real.
import os
# Simulación del LLM: en producción conectas aquí OpenAI, Anthropic o el modelo que uses
def call_llm(messages: list, tools_schema: list) -> dict:
"""
Simula la respuesta del LLM. En producción:
client = anthropic.Anthropic()
response = client.messages.create(model="claude-opus-4-5", ...)
"""
# Lógica simulada: el agente sigue un plan de investigación predecible para el ejemplo
historial_tools = [m.get("tool_called") for m in messages if m.get("role") == "tool_result"]
if "inspect_dataset" not in historial_tools:
return {"action": "tool_call", "tool": "inspect_dataset", "params": {}}
elif "check_nulls_producto" not in historial_tools:
return {"action": "tool_call", "tool": "check_nulls", "params": {"columna": "producto"}, "_tag": "check_nulls_producto"}
elif "check_nulls_monto" not in historial_tools:
return {"action": "tool_call", "tool": "check_nulls", "params": {"columna": "monto"}, "_tag": "check_nulls_monto"}
elif "check_anomalies_monto" not in historial_tools:
return {"action": "tool_call", "tool": "check_anomalies", "params": {"columna": "monto"}, "_tag": "check_anomalies_monto"}
elif "check_anomalies_cantidad" not in historial_tools:
return {"action": "tool_call", "tool": "check_anomalies", "params": {"columna": "cantidad"}, "_tag": "check_anomalies_cantidad"}
elif "generate_report" not in historial_tools:
hallazgos = "Nulos en 'producto': 2.02%. Montos negativos: 23 registros. Outliers en 'cantidad': 8 casos."
return {"action": "tool_call", "tool": "generate_report", "params": {"hallazgos": hallazgos}}
else:
return {"action": "finish", "message": "Investigación completada. Reporte generado."}
def build_tools_schema() -> list:
"""Construye el esquema de herramientas que el LLM puede ver."""
return [
{"name": "inspect_dataset", "description": "Inspecciona la estructura y metadata del dataset.", "params": []},
{"name": "check_nulls", "description": "Analiza valores nulos en una columna.", "params": ["columna"]},
{"name": "check_anomalies", "description": "Detecta anomalías en una columna numérica.", "params": ["columna"]},
{"name": "generate_report", "description": "Genera el reporte final con los hallazgos acumulados.", "params": ["hallazgos"]},
]
def run_adaptive_agent(objetivo: str, action_context: ActionContext, max_iterations: int = 10):
"""
El bucle adaptativo. El corazón del agente autónomo.
"""
print(f"\n{'='*60}")
print(f"🤖 AGENTE INVESTIGADOR - MODO ADAPTATIVO")
print(f"{'='*60}")
print(f"Objetivo: {objetivo}\n")
# Inicializar capabilities
time_cap = TimeAwareCapability()
messages = [{"role": "user", "content": objetivo}]
messages = time_cap.process_prompt(action_context, messages)
tools_schema = build_tools_schema()
iteracion = 0
action_context.set("memory", [])
# --- EL BUCLE ADAPTATIVO ---
while iteracion < max_iterations:
iteracion += 1
print(f"\n--- Iteración {iteracion} ---")
# 1. El LLM razona sobre el estado actual y decide qué hacer
decision = call_llm(messages, tools_schema)
print(f"[LLM decide]: {decision['action']}", end="")
# 2. ¿Terminó?
if decision["action"] == "finish":
print(f" → {decision['message']}")
print(f"\n✅ Agente terminó en {iteracion} iteraciones.")
break
# 3. ¿Llama una herramienta?
if decision["action"] == "tool_call":
tool_name = decision["tool"]
tool_params = decision.get("params", {})
tag = decision.get("_tag", tool_name)
print(f" → llamando '{tool_name}' con params {tool_params}")
# 4. Ejecutar la herramienta real
if tool_name in HERRAMIENTAS_DISPONIBLES:
herramienta = HERRAMIENTAS_DISPONIBLES[tool_name]
resultado = herramienta(action_context, **tool_params)
else:
resultado = json.dumps({"error": f"Herramienta '{tool_name}' no encontrada."})
print(f"[Resultado]: {resultado[:120]}...") # Preview del resultado
# 5. Guardar en memoria con ID (el truco del post anterior, aplicado aquí)
mem_id = f"mem_{iteracion}"
action_context.get("memory").append({
"id": mem_id,
"tool": tool_name,
"resultado": resultado
})
# 6. Añadir al historial de mensajes para que el LLM tenga contexto en la próxima vuelta
messages.append({
"role": "tool_result",
"tool_called": tag,
"content": resultado
})
else:
# El bucle terminó por max_iterations, no por decisión del agente
print(f"\n⚠️ Límite de {max_iterations} iteraciones alcanzado. Forzando cierre.")
return action_context.get("reporte_final")
Qué está pasando aquí:
Esto es el alma del post. Léelo con calma.
El while iteracion < max_iterations es el bucle adaptativo. En cada vuelta, el LLM recibe todo el historial de mensajes acumulado lo que el usuario pidió, lo que ya ejecutó, y los resultados que obtuvo. Con esa información, decide el siguiente paso.
Fíjate en dos cosas críticas:
El agente puede llamar
check_nullsmúltiples veces, con distintas columnas. No hay un flujo que diga "ahora toca columna X". El LLM decide cuántas columnas analizar basándose en lo que va encontrando.El
max_iterationses tu red de seguridad. Si el agente se confunde o entra en un loop, el sistema para limpio. Sin esto, tienes una bomba de tokens activa.
5. Stop conditions: cómo evitar que el agente se pierda para siempre
El mayor riesgo del bucle adaptativo no es que falle. Es que no sepa cuándo parar.
Un agente sin condiciones de parada claras puede entrar en loops, repetir herramientas innecesariamente o seguir buscando información que ya tiene. Yo uso tres capas de control:
class StopConditionCapability(Capability):
"""
Capability que evalúa si el agente debe detenerse antes de la siguiente iteración.
Se ejecuta al final de cada vuelta del bucle.
"""
def __init__(self, max_tool_calls: int = 8, required_tool: str = None):
self.max_tool_calls = max_tool_calls
self.required_tool = required_tool # Herramienta que debe haberse llamado para considerar completo
def should_stop(self, action_context: ActionContext) -> tuple[bool, str]:
memoria = action_context.get("memory", [])
# Capa 1: Límite de llamadas a herramientas
if len(memoria) >= self.max_tool_calls:
return True, f"Límite de {self.max_tool_calls} llamadas alcanzado."
# Capa 2: Herramienta requerida ya fue llamada
if self.required_tool:
tools_llamadas = [m["tool"] for m in memoria]
if self.required_tool in tools_llamadas:
return True, f"Herramienta requerida '{self.required_tool}' ejecutada. Misión cumplida."
# Capa 3: Reporte final ya generado
if action_context.get("reporte_final"):
return True, "Reporte final detectado en contexto. Cierre limpio."
return False, ""
Qué está pasando aquí:
Tres capas, tres criterios distintos. El primero es cuantitativo: no más de N llamadas. El segundo es semántico: ¿ya ejecutaste la herramienta que marca el fin del proceso? El tercero es de estado: ¿ya hay un resultado final en el contexto?
En producción yo combino las tres. Una sola capa te deja puntos ciegos.
Una cosa que no negocio:
Todo agente adaptativo necesita al menos dos condiciones de parada independientes. Una sola es un punto de fallo.
6. In-Loop Planning: el agente que revisa su propio progreso
En el primer post de la serie te hablé del Ahead-of-Time Planning: el agente crea un plan antes de ejecutar nada.
En el modo adaptativo, ese plan se queda enterrado después de 5-6 iteraciones. El agente "olvida" su norte.
Mi solución es el In-Loop Planning: cada cierto número de iteraciones, obligo al agente a generar un reporte de progreso interno.
class InLoopPlanningCapability(Capability):
"""
Cada N iteraciones, el agente hace una pausa y evalúa su propio progreso.
Esto evita que se pierda en iteraciones largas.
"""
def __init__(self, check_every: int = 3):
self.check_every = check_every
def check_progress(self, action_context: ActionContext, iteracion: int) -> str | None:
if iteracion % self.check_every != 0:
return None
memoria = action_context.get("memory", [])
if not memoria:
return None
tools_ejecutadas = [m["tool"] for m in memoria]
reporte_progreso = {
"iteracion_actual": iteracion,
"herramientas_ejecutadas": tools_ejecutadas,
"herramientas_pendientes": [
t for t in HERRAMIENTAS_DISPONIBLES.keys()
if t not in tools_ejecutadas and t != "generate_report"
],
"tiene_reporte": bool(action_context.get("reporte_final"))
}
mensaje_progreso = f"[IN-LOOP CHECK] Iteración {iteracion}: ejecuté {tools_ejecutadas}. Pendiente: {reporte_progreso['herramientas_pendientes']}"
print(f"\n🔍 {mensaje_progreso}")
# Esto se inyecta en el historial de mensajes para que el LLM lo considere
return json.dumps(reporte_progreso)
Qué está pasando aquí:
Cada 3 iteraciones (configurable), el sistema genera un snapshot del estado: qué herramientas ya se llamaron, cuáles faltan, si hay reporte. Ese snapshot se inyecta en el historial de mensajes.
El LLM lo lee en la siguiente vuelta y ajusta su razonamiento. Si ya analizó 4 columnas y tiene suficiente evidencia, puede decidir saltar directo al generate_report en vez de seguir explorando.
Es como el standup diario de un equipo de desarrollo. Corto, preciso, reencuadra el trabajo.
7. Ejecución completa: soltando la bestia
Ahora ensamblamos todo y lo corremos.
def main():
# 1. Preparar el contexto con dependencias
context = ActionContext({
"time_zone": "America/Bogota",
"analista": "Martin Alegria",
"memory": []
})
# 2. Configurar las capabilities
stop_cap = StopConditionCapability(max_tool_calls=8, required_tool="generate_report")
planning_cap = InLoopPlanningCapability(check_every=3)
# 3. El objetivo en lenguaje natural - esto es lo único que el usuario final ve
objetivo = """
Analiza el dataset 'ventas_q1_2025'. Quiero un reporte completo de calidad:
- Estructura del dataset
- Columnas con valores nulos y su impacto
- Anomalías en columnas numéricas críticas
- Hallazgos consolidados al final
No necesito que me preguntes qué columnas revisar. Tú decides el alcance del análisis.
"""
# 4. Inicializar el planning antes de arrancar
planning_cap.check_progress(context, 0)
# 5. Arrancar el bucle adaptativo
reporte = run_adaptive_agent(
objetivo=objetivo,
action_context=context,
max_iterations=10
)
# 6. Mostrar resultado final
if reporte:
print(f"\n{'='*60}")
print("📋 REPORTE FINAL GENERADO")
print('='*60)
print(json.dumps(reporte, indent=2, ensure_ascii=False))
else:
print("\n⚠️ El agente terminó sin generar reporte. Revisar logs.")
# 7. Dump de memoria para auditoría
print(f"\n📦 Memoria del agente ({len(context.get('memory'))} entradas):")
for mem in context.get("memory"):
print(f" [{mem['id']}] {mem['tool']}")
if __name__ == "__main__":
main()
Qué está pasando aquí:
Mira el objetivo que le paso al agente. No le digo "primero llama inspect_dataset, luego check_nulls con columna producto". Le digo qué quiero saber. Él decide el camino.
Eso es la diferencia fundamental con el AI Shim del post anterior.
Y fíjate en la línea final: el dump de memoria. Cada herramienta ejecutada queda registrada con su ID. Eso es mi pista de auditoría. Si el agente toma una decisión rara, puedo rastrear exactamente qué vio y en qué orden.
Al correr esto en tu terminal verás algo así:
============================================================
🤖 AGENTE INVESTIGADOR - MODO ADAPTATIVO
============================================================
Objetivo: Analiza el dataset 'ventas_q1_2025'...
--- Iteración 1 ---
[LLM decide]: tool_call → llamando 'inspect_dataset' con params {}
[Resultado]: {"nombre": "ventas_q1_2025", "total_filas": 15420...
--- Iteración 2 ---
[LLM decide]: tool_call → llamando 'check_nulls' con params {'columna': 'producto'}
[Resultado]: {"columna": "producto", "nulos": 312, "porcentaje": 2.02}...
--- Iteración 3 ---
🔍 [IN-LOOP CHECK] Iteración 3: ejecuté ['inspect_dataset', 'check_nulls']. Pendiente: [...]
--- Iteración 4 ---
[LLM decide]: tool_call → llamando 'check_anomalies' con params {'columna': 'monto'}
...
--- Iteración 6 ---
[LLM decide]: tool_call → llamando 'generate_report' con params {...}
✅ Agente terminó en 7 iteraciones.
Sin que yo le dijera el orden. Sin que yo le dijera cuántas columnas revisar. El agente razonó, actuó, observó y decidió cuándo tenía suficiente para generar el reporte.
Eso es un agente autónomo real.
8. Conclusión: cuándo usar cada modo
Completamos la trilogía.
En el primer post te di los conceptos: prompts como computación, personas, documento como implementación.
En el segundo te di el chasis: ActionContext, Capabilities, seguridad transaccional, el AI Shim.
Hoy soltamos la bestia: el bucle adaptativo completo con stop conditions, in-loop planning y memoria por IDs.
¿Y cuándo usas cada modo en producción real?
AI Shim cuando el proceso es crítico, auditado y el flujo no puede variar. Sistemas financieros, compliance, ETLs de negocio.
Adaptativo cuando el problema es exploratorio, el camino no es predecible y aceptas un costo mayor en tokens a cambio de flexibilidad real. Investigación de datos, análisis de incidentes, exploración de datasets desconocidos.
No hay uno mejor que el otro en términos absolutos. Hay el correcto para cada problema.
Lo que sí es absoluto:
Sin arquitectura sólida, un agente adaptativo es solo un loop de alucinaciones caro.
Con ActionContext, stop conditions bien definidas e in-loop planning, es una herramienta de producción real.
El chasis de titanio aguanta los dos modos. Tú decides cuándo poner los frenos y cuándo quitarlos.
Construye con criterio.
#AIArchitecture #AgenticAI #AutonomousAgents #LLMOps #Python #GenerativeAI #DataScience #MultiAgentSystems #SoftwareEngineering #MachineLearning