Hoy se acabó tanto concepto. Nos vamos a ensuciar las manos.
En el post anterior te di el marco teórico completo de MCP: los tres actores, los cuatro primitivos, los transportes, la seguridad, y cómo se diferencia de APIs, RAG y A2A. Ese era el mapa. Hoy caminamos el territorio.
Vamos a construir dos servidores MCP reales en Python con FastMCP 3.x, el framework que hoy está detrás del 70% de los servidores MCP del ecosistema. No código de tutorial de YouTube código que pasarías en una revisión de pull request: tipado estricto con Pydantic, manejo de errores serio, logging estructurado, configuración por variables de entorno, async donde corresponde y validación en cada borde.
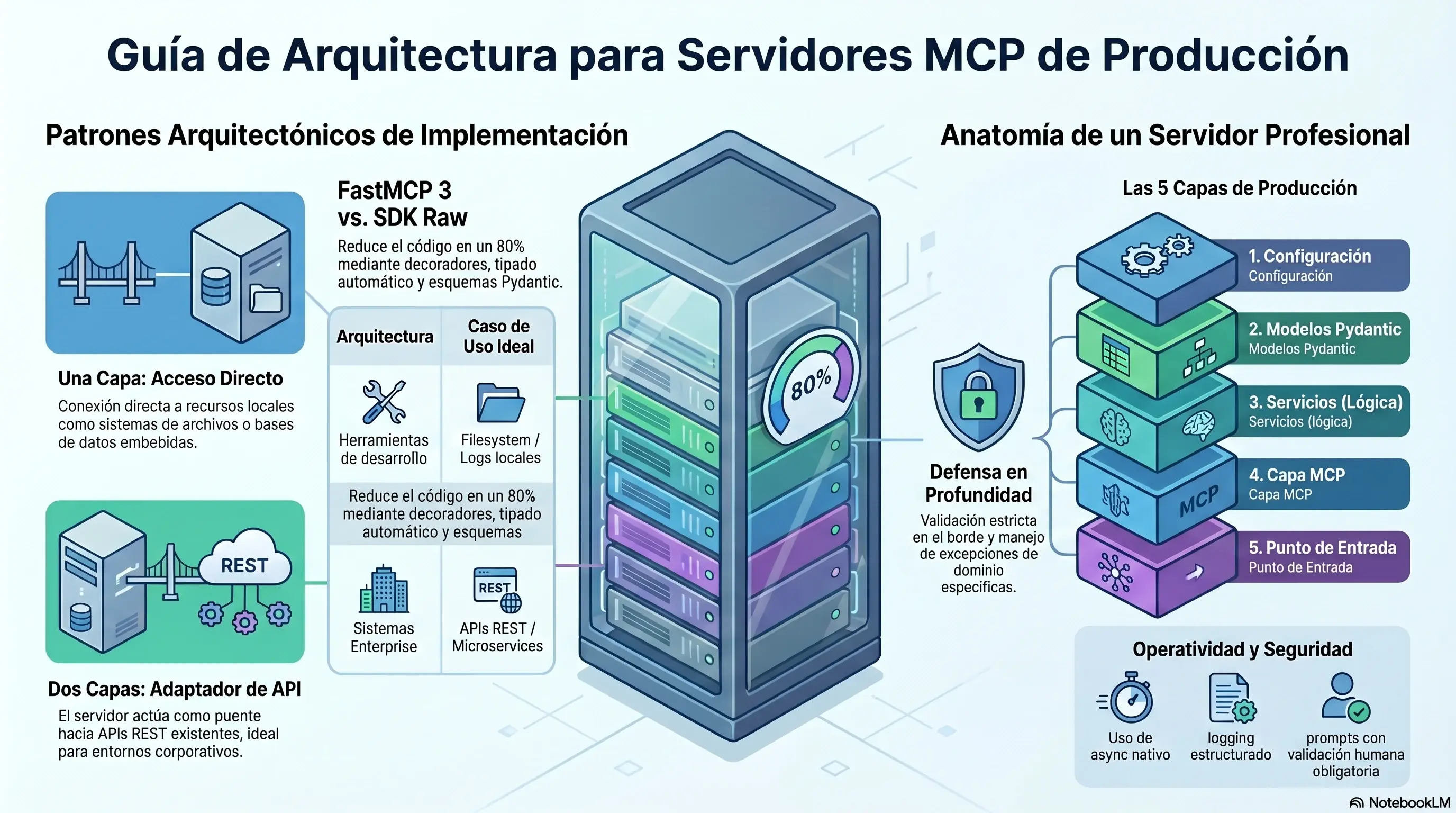
Los dos ejemplos no son arbitrarios. Cada uno representa un patrón arquitectónico que vas a encontrar en producción real:
Ejemplo 1 Una capa: un servidor MCP de análisis de logs de aplicación. El agente puede listar archivos, leer su contenido, contar niveles, buscar patrones. Conexión directa al filesystem.
Ejemplo 2 Dos capas: un servidor MCP que actúa como adaptador de una API REST de gestión de tickets de soporte. El agente habla MCP, el servidor MCP traduce a HTTP, la API maneja la lógica de negocio. El patrón que se usa de verdad en entornos enterprise.
Construir un servidor MCP que funcione es trivial. Construir uno que sea seguro, observable, async-ready y digno de producción es otra historia. Hoy te muestro la diferencia.
📚 Índice del post
Por qué FastMCP 3 y no el SDK raw
Setup del entorno con UV y FastMCP 3.x
La anatomía de un servidor MCP profesional
Ejemplo 1 Servidor MCP de análisis de logs (Una Capa)
Probar el servidor 1 con MCP Inspector
Ejemplo 2 Servidor MCP adaptador de API de tickets (Dos Capas)
Probar el servidor 2 contra la API real
Conectar ambos servidores a Claude Desktop
Patrones de producción que aplicamos
Lo que sigue en la serie MCP
1. Por qué FastMCP 3 y no el SDK raw
Antes de escribir una línea, justifico la decisión técnica. Hay dos formas de construir un servidor MCP en Python en 2026:
Opción A SDK oficial mcp raw: te da control total sobre el protocolo, manejo manual de transports, handlers crudos. Es la opción cuando estás construyendo infraestructura o necesitas comportamiento que se sale del estándar.
Opción B FastMCP 3.x: un framework declarativo construido encima del SDK oficial. Decoradores, tipado automático, schemas generados desde type hints, hot reload, OpenTelemetry nativo, transports gestionados.
¿Cuál uso yo en producción? FastMCP 3, sin dudarlo, salvo casos muy específicos.
Las razones:
Reducción de boilerplate del 80%. Lo que en el SDK raw te toma 50 líneas, en FastMCP son 8.
Schemas Pydantic automáticos. El framework genera el JSON Schema del tool a partir de los type hints y los modelos Pydantic. Cero divergencia entre el código y el contrato.
Funciones siguen siendo funciones. En FastMCP 3, las funciones decoradas se pueden importar, llamar y testear como cualquier función Python normal. En FastMCP 2 esto no era así. Eso cambia todo para los tests unitarios.
OpenTelemetry de fábrica. Cada tool call, cada resource read, cada error queda instrumentado con OTEL sin configuración adicional.
Hot reload con
fastmcp dev. El loop de feedback es inmediato.
El día que necesites algo que FastMCP no soporta, puedes bajar al SDK raw sin reescribir. Pero ese día probablemente no llegue.
Yo escojo FastMCP 3 por el mismo motivo que escojo FastAPI sobre starlette o requests sobre urllib. La capa de abstracción correcta acelera el trabajo serio, no lo simplifica al punto de ser inútil.
2. Setup del entorno con UV y FastMCP 3.x
Crear el proyecto
bash
uv init mcp-servers-tutorial
cd mcp-servers-tutorial
# Anclar Python 3.11 (FastMCP requiere 3.10+)
uv python pin 3.11Instalar dependencias
bash
# FastMCP 3.x versión actual estable
uv add "fastmcp>=3.2.0"
# Cliente HTTP async para el adaptador del Ejemplo 2
uv add httpx
# Pydantic Settings para gestión de configuración por env vars
uv add pydantic-settings
# Para el backend simulado del Ejemplo 2
uv add "fastapi[standard]"
# Logging estructurado de calidad de producción
uv add structlogO todo en una línea:
bash
uv add "fastmcp>=3.2.0" httpx pydantic-settings "fastapi[standard]" structlogEstructura del proyecto
mcp-servers-tutorial/
├── .env
├── .env.example
├── .gitignore
├── pyproject.toml
│
├── ejemplo_1_logs/
│ ├── __init__.py
│ ├── server.py ← Servidor MCP (Una Capa)
│ ├── config.py ← Configuración con pydantic-settings
│ ├── models.py ← Modelos Pydantic
│ ├── services.py ← Lógica de negocio (separada del servidor)
│ └── logs_demo/
│ ├── app.log
│ └── errors.log
│
└── ejemplo_2_tickets/
├── __init__.py
├── backend/
│ ├── __init__.py
│ ├── api.py ← API REST simulada con FastAPI
│ └── store.py ← Repositorio in-memory
├── mcp_server/
│ ├── __init__.py
│ ├── server.py ← Servidor MCP (Dos Capas)
│ ├── client.py ← Cliente HTTP que habla con la API
│ ├── config.py
│ └── models.py ← Modelos Pydantic compartidos
└── ...Qué está pasando aquí:
Esta estructura no es decoración. Refleja principios de diseño concretos:
Separación de responsabilidades. El
server.pysolo orquesta MCP. La lógica de negocio vive enservices.py. Eso te permite testear la lógica sin levantar el servidor.Config centralizada.
config.pyconpydantic-settingscarga todo desde variables de entorno. Nada hardcodeado.El Ejemplo 2 tiene dos paquetes hermanos:
backend/(la API que ya existe) ymcp_server/(el adaptador). Esa separación física refleja la separación de capas.
Archivo .env.example
bash
# .env.example
# --- Ejemplo 1: Servidor de logs ---
LOGS_DIR=./ejemplo_1_logs/logs_demo
LOGS_LOG_LEVEL=INFO
# --- Ejemplo 2: Adaptador de API de tickets ---
TICKETS_API_BASE_URL=http://localhost:8080
TICKETS_API_TIMEOUT_SECONDS=10
TICKETS_API_TOKEN=dev-token-no-prod.gitignore
bash
.env
.venv/
__pycache__/
*.pyc
.pytest_cache/
.ruff_cache/3. La anatomía de un servidor MCP profesional
Antes de escribir el primer servidor, fija este modelo. Todo servidor MCP de producción tiene cinco capas no tres como los tutoriales básicos te muestran:
Configuración variables de entorno tipadas con
pydantic-settings. Nunca hardcodear.Modelos Pydantic models para inputs y outputs. Schemas auto-generados.
Servicios la lógica de negocio. Independiente del servidor MCP. Testeable.
Servidor MCP la capa fina que expone los servicios como Tools y Resources.
Punto de entrada el
mainque selecciona el transport y arranca todo.
Un servidor mal diseñado mezcla las cinco en un solo archivo. Funciona, pero es imposible de testear y un infierno de mantener.
El servidor MCP es la capa más delgada del sistema. Si tu
server.pytiene lógica de negocio, estás haciéndolo mal.
Con eso claro, vamos al primer ejemplo.
4. Ejemplo 1 Servidor MCP de análisis de logs (Una Capa)
El caso de uso
Tienes una carpeta con logs de aplicación. Quieres que un agente pueda:
Listar qué archivos hay y su tamaño
Leer contenido de archivos específicos
Contar líneas por nivel (ERROR / WARNING / INFO)
Buscar patrones específicos con filtro por nivel
Obtener un resumen consolidado de todos los logs
Sin abrir manualmente. El agente investiga por ti.
Arquitectura:
Agente (Claude / GPT / cualquier LLM)
│
▼ (protocolo MCP, transport stdio)
Servidor MCP (FastMCP 3)
│
▼ (acceso directo)
Sistema de archivos
(carpeta de logs)Una capa. Sin servicio intermedio. El servidor MCP habla con el filesystem.
Crear los logs de demostración
bash
mkdir -p ejemplo_1_logs/logs_demo
cat > ejemplo_1_logs/logs_demo/app.log << 'EOF'
2026-05-21 09:14:22 INFO Servicio iniciado correctamente en puerto 8080
2026-05-21 09:14:25 INFO Conexión establecida con base de datos
2026-05-21 09:15:01 WARNING Tiempo de respuesta elevado: 2.3s en /api/users
2026-05-21 09:15:33 ERROR Fallo al consultar tabla 'pedidos': timeout
2026-05-21 09:16:10 INFO Health check OK
2026-05-21 09:16:45 WARNING Memoria al 78% de uso
2026-05-21 09:17:02 ERROR Conexión perdida con Redis cache
2026-05-21 09:17:08 INFO Reconexión Redis exitosa
2026-05-21 09:18:30 INFO Procesados 1240 eventos en última ventana
EOF
cat > ejemplo_1_logs/logs_demo/errors.log << 'EOF'
2026-05-21 09:15:33 ERROR Fallo al consultar tabla 'pedidos': timeout
2026-05-21 09:17:02 ERROR Conexión perdida con Redis cache
2026-05-21 09:22:14 ERROR NullPointerException en módulo de facturación
2026-05-21 09:25:01 ERROR Rate limit excedido para usuario user_4421
EOFCapa 1 Configuración (ejemplo_1_logs/config.py)
python
"""Configuración del servidor MCP de análisis de logs."""
from pathlib import Path
from pydantic_settings import BaseSettings, SettingsConfigDict
class Settings(BaseSettings):
"""Configuración cargada desde variables de entorno con prefijo LOGS_."""
model_config = SettingsConfigDict(
env_file=".env",
env_file_encoding="utf-8",
env_prefix="LOGS_",
extra="ignore",
)
dir: Path = Path("./ejemplo_1_logs/logs_demo")
log_level: str = "INFO"
max_search_results: int = 100
max_file_size_mb: float = 50.0
settings = Settings()Qué está pasando aquí:
pydantic-settings valida la configuración al arrancar el servidor. Si una variable está mal definida, el servidor falla rápido antes de aceptar la primera request. Eso es lo que quieres. Un servidor que arranca con config corrupta y muere a la décima request es lo peor.
El env_prefix="LOGS_" me permite tener variables del Ejemplo 1 y del Ejemplo 2 en el mismo .env sin colisión.
Capa 2 Modelos (ejemplo_1_logs/models.py)
python
"""Modelos Pydantic para inputs y outputs del servidor MCP de logs."""
from typing import Literal
from pydantic import BaseModel, Field
NivelLog = Literal["ERROR", "WARNING", "INFO", "TODOS"]
class ArchivoLog(BaseModel):
"""Metadata de un archivo de log."""
nombre: str
tamano_kb: float = Field(description="Tamaño del archivo en KB")
ultima_modificacion: str = Field(description="ISO timestamp de última modificación")
class ConteoNiveles(BaseModel):
"""Resultado de contar líneas por nivel en un archivo de log."""
archivo: str
total_lineas: int = Field(ge=0)
errores: int = Field(ge=0)
warnings: int = Field(ge=0)
info: int = Field(ge=0)
class CoincidenciaBusqueda(BaseModel):
"""Una coincidencia encontrada al buscar un patrón."""
archivo: str
linea_numero: int = Field(ge=1)
contenido: str
nivel_detectado: str | None = None
class ResumenGlobal(BaseModel):
"""Resumen consolidado de todos los archivos de log."""
archivos_analizados: list[str]
total_archivos: int = Field(ge=0)
total_lineas: int = Field(ge=0)
total_errores: int = Field(ge=0)
total_warnings: int = Field(ge=0)
archivo_con_mas_errores: str | None = NoneQué está pasando aquí:
Cada modelo es la frontera de un contrato. Cuando el LLM invoca una tool, recibe exactamente este shape validado por Pydantic, garantizado por el framework. No "el modelo a veces devuelve un string, a veces un dict". Cero ambigüedad en los outputs.
Los Field(ge=0) añaden constraints adicionales: los conteos nunca pueden ser negativos. Pydantic los valida automáticamente.
Capa 3 Servicios (ejemplo_1_logs/services.py)
Aquí vive la lógica real. Sin saber nada de MCP. Solo Python puro.
python
"""Lógica de negocio del análisis de logs. Independiente del transporte MCP."""
from datetime import datetime
from pathlib import Path
import structlog
from .config import settings
from .models import ArchivoLog, ConteoNiveles, CoincidenciaBusqueda, NivelLog, ResumenGlobal
log = structlog.get_logger(__name__)
class LogAnalysisError(Exception):
"""Excepción base para errores del servicio de análisis de logs."""
class ArchivoNoEncontrado(LogAnalysisError):
"""El archivo solicitado no existe."""
class NombreArchivoInvalido(LogAnalysisError):
"""El nombre del archivo contiene caracteres no permitidos."""
def _validar_nombre_archivo(nombre: str) -> None:
"""Previene path traversal y otros ataques basados en el nombre."""
if not nombre or len(nombre) > 255:
raise NombreArchivoInvalido("Nombre vacío o demasiado largo")
if any(c in nombre for c in ["/", "\\", ".."]):
raise NombreArchivoInvalido(f"Caracteres prohibidos en '{nombre}'")
if not nombre.endswith(".log"):
raise NombreArchivoInvalido(f"Solo se permiten archivos .log, recibido '{nombre}'")
def _resolver_path(nombre: str) -> Path:
"""Valida el nombre y devuelve el path absoluto seguro."""
_validar_nombre_archivo(nombre)
archivo = (settings.dir / nombre).resolve()
# Doble verificación: el path resuelto sigue dentro del directorio permitido
if not archivo.is_relative_to(settings.dir.resolve()):
raise NombreArchivoInvalido(f"Path traversal detectado en '{nombre}'")
if not archivo.exists() or not archivo.is_file():
raise ArchivoNoEncontrado(f"Archivo '{nombre}' no encontrado")
tamano_mb = archivo.stat().st_size / (1024 * 1024)
if tamano_mb > settings.max_file_size_mb:
raise LogAnalysisError(
f"Archivo '{nombre}' excede el límite de {settings.max_file_size_mb} MB"
)
return archivo
def listar_archivos() -> list[ArchivoLog]:
"""Lista todos los archivos .log del directorio configurado."""
log.info("listar_archivos", dir=str(settings.dir))
if not settings.dir.exists():
log.warning("directorio_no_existe", dir=str(settings.dir))
return []
archivos: list[ArchivoLog] = []
for path in sorted(settings.dir.glob("*.log")):
stat = path.stat()
archivos.append(ArchivoLog(
nombre=path.name,
tamano_kb=round(stat.st_size / 1024, 2),
ultima_modificacion=datetime.fromtimestamp(stat.st_mtime).isoformat(),
))
return archivos
def leer_archivo(nombre: str) -> str:
"""Lee el contenido completo de un archivo de log."""
log.info("leer_archivo", nombre=nombre)
archivo = _resolver_path(nombre)
return archivo.read_text(encoding="utf-8")
def contar_niveles(nombre: str) -> ConteoNiveles:
"""Cuenta cuántas líneas hay de cada nivel en un archivo de log."""
log.info("contar_niveles", nombre=nombre)
archivo = _resolver_path(nombre)
lineas = archivo.read_text(encoding="utf-8").splitlines()
return ConteoNiveles(
archivo=nombre,
total_lineas=len(lineas),
errores=sum(1 for l in lineas if "ERROR" in l),
warnings=sum(1 for l in lineas if "WARNING" in l),
info=sum(1 for l in lineas if "INFO" in l),
)
def _detectar_nivel(linea: str) -> str | None:
"""Detecta el nivel de log presente en una línea."""
for nivel in ("ERROR", "WARNING", "INFO"):
if nivel in linea:
return nivel
return None
def buscar_patron(
patron: str,
nivel: NivelLog = "TODOS",
limite: int = 20,
) -> list[CoincidenciaBusqueda]:
"""Busca un patrón de texto en todos los logs, con filtro opcional por nivel."""
log.info("buscar_patron", patron=patron, nivel=nivel, limite=limite)
if len(patron.strip()) < 2:
raise ValueError("El patrón debe tener al menos 2 caracteres")
limite_efectivo = min(limite, settings.max_search_results)
resultados: list[CoincidenciaBusqueda] = []
patron_lower = patron.lower()
for archivo in sorted(settings.dir.glob("*.log")):
contenido = archivo.read_text(encoding="utf-8")
for num_linea, linea in enumerate(contenido.splitlines(), start=1):
if patron_lower not in linea.lower():
continue
if nivel != "TODOS" and nivel not in linea:
continue
resultados.append(CoincidenciaBusqueda(
archivo=archivo.name,
linea_numero=num_linea,
contenido=linea.strip(),
nivel_detectado=_detectar_nivel(linea),
))
if len(resultados) >= limite_efectivo:
return resultados
return resultados
def resumen_global() -> ResumenGlobal:
"""Genera un resumen consolidado de todos los archivos de log."""
log.info("resumen_global")
if not settings.dir.exists():
return ResumenGlobal(
archivos_analizados=[],
total_archivos=0,
total_lineas=0,
total_errores=0,
total_warnings=0,
)
archivos = sorted(settings.dir.glob("*.log"))
total_lineas = 0
total_errores = 0
total_warnings = 0
max_errores = 0
archivo_top: str | None = None
nombres: list[str] = []
for archivo in archivos:
contenido = archivo.read_text(encoding="utf-8")
lineas = contenido.splitlines()
errores_archivo = sum(1 for l in lineas if "ERROR" in l)
total_lineas += len(lineas)
total_errores += errores_archivo
total_warnings += sum(1 for l in lineas if "WARNING" in l)
nombres.append(archivo.name)
if errores_archivo > max_errores:
max_errores = errores_archivo
archivo_top = archivo.name
return ResumenGlobal(
archivos_analizados=nombres,
total_archivos=len(archivos),
total_lineas=total_lineas,
total_errores=total_errores,
total_warnings=total_warnings,
archivo_con_mas_errores=archivo_top,
)Qué está pasando aquí:
Lee este código con calma. Hay decisiones críticas en cada parte:
validarnombre_archivo y resolverpath defensa en profundidad. No basta con una validación. Yo valido el nombre (caracteres permitidos, extensión), luego resuelvo el path absoluto, y verifico que el path resuelto siga dentro del directorio permitido. Esa última verificación detecta ataques de symlinks que la validación de nombre no atrapa.
Excepciones de dominio propias. ArchivoNoEncontrado, NombreArchivoInvalido, LogAnalysisError. No uso ValueError genérico. Cuando el servidor MCP capture esto, va a saber exactamente cómo mapear cada tipo a un mensaje útil para el agente.
Logging estructurado con structlog. Cada operación genera un log evento con campos clave-valor. En producción esto va a Datadog, Splunk o Grafana Loki donde puedo filtrar por tool=buscar_patron y ver todas las llamadas.
Sin dependencias de MCP. Importa config, models, structlog. No importa nada de FastMCP. Eso significa que puedo testear este módulo entero sin levantar el servidor.
Capa 4 + 5 Servidor MCP (ejemplo_1_logs/server.py)
Aquí es donde FastMCP brilla. La capa más fina del sistema.
python
"""
Servidor MCP de Análisis de Logs.
Arquitectura: Una Capa (conexión directa al filesystem).
Ejecutar:
fastmcp dev ejemplo_1_logs/server.py # modo desarrollo con hot reload
uv run python ejemplo_1_logs/server.py # modo producción
"""
from typing import Annotated
import structlog
from fastmcp import FastMCP
from pydantic import Field
from . import services
from .models import (
ArchivoLog,
ConteoNiveles,
CoincidenciaBusqueda,
NivelLog,
ResumenGlobal,
)
# Logging estructurado
log = structlog.get_logger(__name__)
# Instancia del servidor MCP
mcp = FastMCP(
name="log-analyzer",
instructions=(
"Servidor MCP de análisis de logs de aplicación. "
"Permite listar archivos, leer contenido, contar niveles "
"(ERROR/WARNING/INFO) y buscar patrones específicos."
),
)
# ---------------------------------------------------------------------------
# RESOURCES exposición de datos como recursos navegables
# ---------------------------------------------------------------------------
@mcp.resource(
uri="logs://files",
name="Listado de archivos de log",
description="Lista todos los archivos .log disponibles con su metadata.",
mime_type="application/json",
)
def resource_listar_archivos() -> list[ArchivoLog]:
"""Lista todos los archivos de log disponibles en el directorio configurado."""
return services.listar_archivos()
@mcp.resource(
uri="logs://content/{nombre_archivo}",
name="Contenido de archivo de log",
description="Devuelve el contenido completo de un archivo de log específico.",
mime_type="text/plain",
)
def resource_leer_archivo(nombre_archivo: str) -> str:
"""Lee el contenido completo de un archivo de log específico."""
try:
return services.leer_archivo(nombre_archivo)
except services.ArchivoNoEncontrado as e:
log.warning("archivo_no_encontrado", nombre=nombre_archivo)
return f"Error: {e}"
except services.NombreArchivoInvalido as e:
log.warning("nombre_archivo_invalido", nombre=nombre_archivo, error=str(e))
return f"Error de validación: {e}"
# ---------------------------------------------------------------------------
# TOOLS acciones que el agente puede ejecutar
# ---------------------------------------------------------------------------
@mcp.tool(
name="contar_niveles_log",
description=(
"Cuenta cuántas líneas hay de cada nivel (ERROR, WARNING, INFO) "
"en un archivo de log específico. Devuelve un desglose numérico."
),
)
def tool_contar_niveles(
nombre_archivo: Annotated[
str,
Field(description="Nombre del archivo .log a analizar", examples=["app.log"]),
],
) -> ConteoNiveles:
try:
return services.contar_niveles(nombre_archivo)
except services.ArchivoNoEncontrado as e:
raise ValueError(f"Archivo no encontrado: {nombre_archivo}") from e
except services.NombreArchivoInvalido as e:
raise ValueError(f"Nombre de archivo inválido: {e}") from e
@mcp.tool(
name="buscar_patron_en_logs",
description=(
"Busca un patrón de texto en todos los archivos de log. "
"Permite filtrar por nivel y limitar resultados. "
"Búsqueda case-insensitive."
),
)
def tool_buscar_patron(
patron: Annotated[
str,
Field(min_length=2, description="Texto a buscar (mínimo 2 caracteres)"),
],
nivel: Annotated[
NivelLog,
Field(description="Filtrar por nivel específico, o TODOS para no filtrar"),
] = "TODOS",
limite: Annotated[
int,
Field(ge=1, le=100, description="Máximo de resultados (1-100)"),
] = 20,
) -> list[CoincidenciaBusqueda]:
try:
return services.buscar_patron(patron=patron, nivel=nivel, limite=limite)
except ValueError as e:
raise ValueError(f"Búsqueda inválida: {e}") from e
@mcp.tool(
name="resumen_global_logs",
description=(
"Genera un resumen consolidado de todos los archivos de log: "
"total de líneas, errores totales, warnings totales, archivos analizados "
"y cuál archivo tiene más errores."
),
)
def tool_resumen_global() -> ResumenGlobal:
return services.resumen_global()
# ---------------------------------------------------------------------------
# PROMPTS plantillas reutilizables para tareas comunes
# ---------------------------------------------------------------------------
@mcp.prompt(
name="analizar_incidente",
description=(
"Plantilla para que el agente analice un incidente a partir de los logs, "
"buscando errores relacionados y sugiriendo causas raíz."
),
)
def prompt_analizar_incidente(componente: str) -> str:
"""Genera el prompt estructurado para análisis de incidente."""
return (
f"Analiza los logs disponibles para identificar incidentes relacionados con '{componente}'.\n\n"
"Sigue estos pasos:\n"
"1. Usa la tool 'resumen_global_logs' para tener una vista general\n"
"2. Usa 'buscar_patron_en_logs' con el nombre del componente y nivel=ERROR\n"
"3. Identifica el archivo con más errores relacionados\n"
"4. Lee ese archivo completo via el recurso logs://content/{nombre}\n"
"5. Construye un reporte con: cronología, errores encontrados, posible causa raíz\n\n"
f"Componente a analizar: {componente}"
)
# ---------------------------------------------------------------------------
# Punto de entrada
# ---------------------------------------------------------------------------
if __name__ == "__main__":
log.info("server_starting", name="log-analyzer", transport="stdio")
mcp.run(transport="stdio")Qué está pasando aquí:
Mira lo delgado que es. Cada función decorada es un wrapper de 2-5 líneas que llama al servicio. Cero lógica de negocio. Esto es lo que yo quiero ver en una revisión de PR.
Annotated[Tipo, Field(...)] es el patrón moderno. FastMCP 3 lee tanto el tipo como los metadata del Field para generar el JSON Schema que ve el LLM. El LLM verá min_length, examples, description todo lo que el agente necesita para invocar la tool correctamente.
Manejo de errores limpio en las Tools. Las excepciones de dominio del servicio se mapean a ValueError con un mensaje útil. FastMCP lo serializa al protocolo MCP correctamente. El agente recibe un error legible, no un stack trace.
Resources con URI parametrizada. logs://content/{nombre_archivo} permite al agente navegar archivos por nombre, como navegaría URLs en una web.
Prompts reutilizables. El prompt_analizar_incidente le dice al agente exactamente qué tools usar y en qué orden para un análisis de incidente. Eso es Documento como Implementación aplicado a prompts.
5. Probar el servidor 1 con MCP Inspector
FastMCP trae el comando fastmcp dev que levanta el servidor con hot reload y abre el MCP Inspector la UI web oficial para testear servidores MCP.
bash
# Desde la raíz del proyecto
uv run fastmcp dev ejemplo_1_logs/server.pyTe imprime una URL (típicamente http://localhost:5173). Ábrela.
En la UI verás tres pestañas: Tools, Resources, Prompts.
Probar Resources:
Pestaña Resources →
logs://files→ "Read"Te devuelve el array JSON con los archivos y su metadata
Probar Tools:
Pestaña Tools →
contar_niveles_logIngresa
nombre_archivo: app.log→ "Run Tool"Resultado esperado:
json
{
"archivo": "app.log",
"total_lineas": 9,
"errores": 2,
"warnings": 2,
"info": 5
}Prueba
buscar_patron_en_logsconpatron: "Redis",nivel: "ERROR",limite: 10Verás la coincidencia exacta
Probar la validación de seguridad:
En
contar_niveles_log, ingresanombre_archivo: ../../../etc/passwdEl servidor rechaza la petición con
Nombre de archivo inválidola defensa en profundidad funciona
Qué está pasando aquí:
El Inspector es tu loop de feedback. Nunca conectes un servidor MCP a un agente real sin haberlo validado primero aquí. Si Inspector lo puede invocar correctamente, el LLM también podrá. Si Inspector falla, el LLM va a fallar peor.
6. Ejemplo 2 Servidor MCP adaptador de API de tickets (Dos Capas)
Aquí cambia todo. Ya no estamos construyendo un servidor que habla con archivos locales. Estamos construyendo un adaptador entre un agente de IA y un sistema enterprise existente.
El caso de uso
Tu empresa tiene un sistema de tickets de soporte. La API REST ya existe la usan el frontend, los integradores externos, las herramientas internas. Tiene autenticación, validación, persistencia, hooks de notificación.
Tú no quieres reescribir esa lógica. Quieres que un agente de IA pueda crear tickets, consultar el estado, actualizar prioridades. Sin tocar la API. Sin duplicar la lógica.
Arquitectura dos capas:
Agente
│
▼ (protocolo MCP)
Servidor MCP Adaptador ←── Esta es la capa que construimos
│ Habla MCP arriba, HTTP abajo
▼ (HTTP / REST)
API de Tickets ←── Ya existe, no la tocamos
│
▼
Base de datosBackend: la API que "ya existe"
Para que el ejemplo sea ejecutable end-to-end, simulo la API interna con FastAPI. En tu caso real, este componente ya existe tú solo construyes el servidor MCP que la consume.
ejemplo_2_tickets/backend/store.py:
python
"""Repositorio in-memory para tickets simula la persistencia."""
from datetime import datetime, timezone
from threading import Lock
from uuid import uuid4
from ..mcp_server.models import Ticket, TicketCreate, TicketUpdate
class TicketStore:
"""Store thread-safe en memoria para tickets de soporte."""
def __init__(self) -> None:
self._tickets: dict[str, Ticket] = {}
self._lock = Lock()
self._seed_demo_data()
def _seed_demo_data(self) -> None:
"""Crea algunos tickets de ejemplo al iniciar."""
demo = [
TicketCreate(
titulo="Error 500 al acceder a /reports",
descripcion="Los usuarios reportan error 500 al cargar el dashboard de reportes desde las 09:00",
prioridad="alta",
cliente_id="CLI-0042",
),
TicketCreate(
titulo="Solicitud de nueva funcionalidad: exportar PDF",
descripcion="Cliente solicita poder exportar facturas en PDF además del actual CSV",
prioridad="baja",
cliente_id="CLI-0099",
),
]
for t in demo:
self.create(t)
def create(self, data: TicketCreate) -> Ticket:
with self._lock:
now = datetime.now(timezone.utc)
ticket_id = f"TKT-{uuid4().hex[:8].upper()}"
ticket = Ticket(
id=ticket_id,
titulo=data.titulo,
descripcion=data.descripcion,
prioridad=data.prioridad,
estado="abierto",
cliente_id=data.cliente_id,
creado_en=now,
actualizado_en=now,
)
self._tickets[ticket_id] = ticket
return ticket
def get(self, ticket_id: str) -> Ticket | None:
return self._tickets.get(ticket_id)
def list_by_estado(self, estado: str | None = None) -> list[Ticket]:
with self._lock:
todos = list(self._tickets.values())
if estado is None:
return todos
return [t for t in todos if t.estado == estado]
def update(self, ticket_id: str, data: TicketUpdate) -> Ticket | None:
with self._lock:
ticket = self._tickets.get(ticket_id)
if ticket is None:
return None
actualizado = ticket.model_copy(update={
**data.model_dump(exclude_none=True),
"actualizado_en": datetime.now(timezone.utc),
})
self._tickets[ticket_id] = actualizado
return actualizado
store = TicketStore()ejemplo_2_tickets/backend/api.py:
python
"""API REST de Tickets el sistema enterprise existente, simulado con FastAPI."""
from fastapi import Depends, FastAPI, Header, HTTPException, status
from ..mcp_server.models import Ticket, TicketCreate, TicketUpdate
from .store import store
API_TOKEN = "dev-token-no-prod" # En producción: secrets manager, no hardcoded
app = FastAPI(title="API de Tickets", version="1.0.0")
def verificar_token(authorization: str = Header(default="")) -> None:
"""Autenticación Bearer simple. Producción real usa OAuth2."""
if not authorization.startswith("Bearer "):
raise HTTPException(status.HTTP_401_UNAUTHORIZED, "Token requerido")
token = authorization.removeprefix("Bearer ").strip()
if token != API_TOKEN:
raise HTTPException(status.HTTP_401_UNAUTHORIZED, "Token inválido")
@app.get("/health")
def health() -> dict:
return {"status": "ok"}
@app.post("/tickets", response_model=Ticket, status_code=status.HTTP_201_CREATED,
dependencies=[Depends(verificar_token)])
def crear_ticket(payload: TicketCreate) -> Ticket:
return store.create(payload)
@app.get("/tickets", response_model=list[Ticket],
dependencies=[Depends(verificar_token)])
def listar_tickets(estado: str | None = None) -> list[Ticket]:
return store.list_by_estado(estado)
@app.get("/tickets/{ticket_id}", response_model=Ticket,
dependencies=[Depends(verificar_token)])
def obtener_ticket(ticket_id: str) -> Ticket:
ticket = store.get(ticket_id)
if ticket is None:
raise HTTPException(status.HTTP_404_NOT_FOUND, f"Ticket {ticket_id} no encontrado")
return ticket
@app.patch("/tickets/{ticket_id}", response_model=Ticket,
dependencies=[Depends(verificar_token)])
def actualizar_ticket(ticket_id: str, payload: TicketUpdate) -> Ticket:
ticket = store.update(ticket_id, payload)
if ticket is None:
raise HTTPException(status.HTTP_404_NOT_FOUND, f"Ticket {ticket_id} no encontrado")
return ticketModelos compartidos
ejemplo_2_tickets/mcp_server/models.py:
python
"""Modelos Pydantic compartidos entre la API y el servidor MCP."""
from datetime import datetime
from typing import Literal
from pydantic import BaseModel, Field
Estado = Literal["abierto", "en_progreso", "resuelto", "cerrado"]
Prioridad = Literal["baja", "media", "alta", "critica"]
class TicketCreate(BaseModel):
"""Payload para crear un nuevo ticket."""
titulo: str = Field(min_length=5, max_length=200,
description="Título corto del ticket")
descripcion: str = Field(min_length=10, max_length=2000,
description="Descripción detallada del problema")
prioridad: Prioridad = Field(default="media",
description="Prioridad inicial del ticket")
cliente_id: str = Field(pattern=r"^CLI-\d{4}$",
description="ID del cliente afectado (formato CLI-####)",
examples=["CLI-0042"])
class Ticket(BaseModel):
"""Ticket completo tal como lo devuelve la API."""
id: str
titulo: str
descripcion: str
prioridad: Prioridad
estado: Estado
cliente_id: str
creado_en: datetime
actualizado_en: datetime
class TicketUpdate(BaseModel):
"""Payload para actualizar un ticket existente."""
estado: Estado | None = None
prioridad: Prioridad | None = NoneCapa de configuración
ejemplo_2_tickets/mcp_server/config.py:
python
"""Configuración del adaptador MCP de tickets."""
from pydantic import SecretStr
from pydantic_settings import BaseSettings, SettingsConfigDict
class Settings(BaseSettings):
"""Configuración del adaptador MCP, prefijo TICKETS_."""
model_config = SettingsConfigDict(
env_file=".env",
env_file_encoding="utf-8",
env_prefix="TICKETS_",
extra="ignore",
)
api_base_url: str = "http://localhost:8080"
api_timeout_seconds: float = 10.0
api_token: SecretStr = SecretStr("dev-token-no-prod")
max_results_per_page: int = 50
settings = Settings()Qué está pasando aquí:
SecretStr de Pydantic evita que el token aparezca en logs accidentales o en repr(). Si alguien hace print(settings), ve api_token=SecretStr('**********') en lugar del token real. Es una protección pequeña pero importante.
Cliente HTTP la capa de adaptación
ejemplo_2_tickets/mcp_server/client.py:
python
"""Cliente HTTP async que habla con la API REST de tickets."""
from typing import Any
import httpx
import structlog
from .config import settings
from .models import Ticket, TicketCreate, TicketUpdate
log = structlog.get_logger(__name__)
class TicketsApiError(Exception):
"""Error genérico del cliente de la API de tickets."""
class TicketNotFound(TicketsApiError):
"""El ticket solicitado no existe en la API."""
class TicketsApiClient:
"""Cliente async para la API REST de tickets.
Gestiona conexión, autenticación y mapeo de errores HTTP a excepciones de dominio.
"""
def __init__(self) -> None:
self._client = httpx.AsyncClient(
base_url=settings.api_base_url,
timeout=settings.api_timeout_seconds,
headers={
"Authorization": f"Bearer {settings.api_token.get_secret_value()}",
"Content-Type": "application/json",
"User-Agent": "mcp-tickets-adapter/1.0",
},
)
async def close(self) -> None:
await self._client.aclose()
async def _request(self, method: str, path: str, **kwargs: Any) -> httpx.Response:
try:
response = await self._client.request(method, path, **kwargs)
except httpx.TimeoutException as e:
log.error("api_timeout", method=method, path=path)
raise TicketsApiError(f"Timeout llamando a {path}") from e
except httpx.RequestError as e:
log.error("api_request_error", method=method, path=path, error=str(e))
raise TicketsApiError(f"Error de conexión: {e}") from e
if response.status_code == 404:
raise TicketNotFound(f"Recurso no encontrado: {path}")
if response.status_code >= 400:
log.error("api_http_error", status=response.status_code, body=response.text)
raise TicketsApiError(
f"Error HTTP {response.status_code}: {response.text[:200]}"
)
return response
async def crear_ticket(self, data: TicketCreate) -> Ticket:
log.info("crear_ticket", cliente_id=data.cliente_id, prioridad=data.prioridad)
response = await self._request("POST", "/tickets", json=data.model_dump())
return Ticket.model_validate(response.json())
async def obtener_ticket(self, ticket_id: str) -> Ticket:
log.info("obtener_ticket", ticket_id=ticket_id)
response = await self._request("GET", f"/tickets/{ticket_id}")
return Ticket.model_validate(response.json())
async def listar_tickets(self, estado: str | None = None) -> list[Ticket]:
log.info("listar_tickets", estado=estado)
params = {"estado": estado} if estado else None
response = await self._request("GET", "/tickets", params=params)
return [Ticket.model_validate(t) for t in response.json()]
async def actualizar_ticket(self, ticket_id: str, data: TicketUpdate) -> Ticket:
log.info("actualizar_ticket", ticket_id=ticket_id,
cambios=data.model_dump(exclude_none=True))
response = await self._request(
"PATCH",
f"/tickets/{ticket_id}",
json=data.model_dump(exclude_none=True),
)
return Ticket.model_validate(response.json())
client = TicketsApiClient()Qué está pasando aquí:
Esta es la capa más importante de la arquitectura de dos capas. Lee con calma:
Async de punta a punta. httpx.AsyncClient es el cliente HTTP async de referencia en Python moderno. FastMCP soporta tools async nativamente las llamadas a la API no bloquean el servidor.
Mapeo de errores HTTP a excepciones de dominio. 404 → TicketNotFound, otros errores → TicketsApiError, timeouts → TicketsApiError. El servidor MCP captura las excepciones de dominio, no códigos HTTP. Eso es separación correcta de niveles.
El token nunca aparece en logs. settings.api_token.get_secret_value() lo extrae solo donde se necesita.
User-Agent identificable. En producción, eso te permite filtrar en los logs de la API: "¿quién está llamando, el frontend o el agente MCP?"
El servidor MCP tools async
ejemplo_2_tickets/mcp_server/server.py:
python
"""
Servidor MCP de Tickets Adaptador de la API REST interna.
Arquitectura: Dos Capas (MCP → HTTP → API → DB).
Ejecutar:
1. Levantar el backend: uv run uvicorn ejemplo_2_tickets.backend.api:app --port 8080
2. Levantar el MCP: fastmcp dev ejemplo_2_tickets/mcp_server/server.py
"""
from typing import Annotated
import structlog
from fastmcp import FastMCP
from pydantic import Field
from .client import TicketNotFound, TicketsApiError, client
from .models import Estado, Prioridad, Ticket, TicketCreate, TicketUpdate
log = structlog.get_logger(__name__)
mcp = FastMCP(
name="tickets-adapter",
instructions=(
"Servidor MCP adaptador del sistema de tickets de soporte. "
"Permite crear, consultar, listar y actualizar tickets a través "
"de la API REST interna. Toda acción se ejecuta contra el sistema real."
),
)
# ---------------------------------------------------------------------------
# RESOURCES exposición de datos
# ---------------------------------------------------------------------------
@mcp.resource(
uri="tickets://all",
name="Listado completo de tickets",
description="Devuelve todos los tickets del sistema, sin filtrar.",
mime_type="application/json",
)
async def resource_listar_tickets() -> list[Ticket]:
return await client.listar_tickets()
@mcp.resource(
uri="tickets://by-estado/{estado}",
name="Tickets por estado",
description="Lista tickets filtrados por estado (abierto, en_progreso, resuelto, cerrado).",
mime_type="application/json",
)
async def resource_tickets_por_estado(estado: str) -> list[Ticket]:
return await client.listar_tickets(estado=estado)
@mcp.resource(
uri="tickets://detail/{ticket_id}",
name="Detalle de ticket",
description="Devuelve el detalle completo de un ticket por su ID.",
mime_type="application/json",
)
async def resource_obtener_ticket(ticket_id: str) -> Ticket | dict:
try:
return await client.obtener_ticket(ticket_id)
except TicketNotFound:
return {"error": f"Ticket {ticket_id} no encontrado"}
# ---------------------------------------------------------------------------
# TOOLS acciones contra el sistema real
# ---------------------------------------------------------------------------
@mcp.tool(
name="crear_ticket_soporte",
description=(
"Crea un nuevo ticket de soporte en el sistema. "
"Requiere título, descripción y cliente_id en formato CLI-####. "
"Devuelve el ticket creado con su ID asignado."
),
)
async def tool_crear_ticket(
titulo: Annotated[
str,
Field(min_length=5, max_length=200,
description="Título conciso del ticket",
examples=["Error al exportar reporte mensual"]),
],
descripcion: Annotated[
str,
Field(min_length=10, max_length=2000,
description="Descripción detallada del problema con contexto"),
],
cliente_id: Annotated[
str,
Field(pattern=r"^CLI-\d{4}$",
description="ID del cliente afectado (formato CLI-####)",
examples=["CLI-0042"]),
],
prioridad: Annotated[
Prioridad,
Field(description="Prioridad inicial del ticket"),
] = "media",
) -> Ticket:
payload = TicketCreate(
titulo=titulo,
descripcion=descripcion,
prioridad=prioridad,
cliente_id=cliente_id,
)
try:
return await client.crear_ticket(payload)
except TicketsApiError as e:
log.error("crear_ticket_fallo", error=str(e))
raise ValueError(f"Error creando ticket: {e}") from e
@mcp.tool(
name="actualizar_estado_ticket",
description=(
"Actualiza el estado y/o prioridad de un ticket existente. "
"Al menos uno de los dos parámetros opcionales debe ir."
),
)
async def tool_actualizar_ticket(
ticket_id: Annotated[
str,
Field(pattern=r"^TKT-[A-F0-9]{8}$",
description="ID del ticket (formato TKT-XXXXXXXX)"),
],
nuevo_estado: Annotated[
Estado | None,
Field(description="Nuevo estado del ticket"),
] = None,
nueva_prioridad: Annotated[
Prioridad | None,
Field(description="Nueva prioridad del ticket"),
] = None,
) -> Ticket:
if nuevo_estado is None and nueva_prioridad is None:
raise ValueError("Debes proveer al menos nuevo_estado o nueva_prioridad")
payload = TicketUpdate(estado=nuevo_estado, prioridad=nueva_prioridad)
try:
return await client.actualizar_ticket(ticket_id, payload)
except TicketNotFound:
raise ValueError(f"Ticket {ticket_id} no existe") from None
except TicketsApiError as e:
raise ValueError(f"Error actualizando ticket: {e}") from e
@mcp.tool(
name="resumen_tickets_abiertos",
description=(
"Genera un resumen rápido de los tickets en estado 'abierto', "
"agrupados por prioridad. Útil para triaging."
),
)
async def tool_resumen_tickets_abiertos() -> dict[str, int]:
abiertos = await client.listar_tickets(estado="abierto")
resumen: dict[str, int] = {"baja": 0, "media": 0, "alta": 0, "critica": 0}
for t in abiertos:
resumen[t.prioridad] += 1
resumen["total"] = len(abiertos)
return resumen
# ---------------------------------------------------------------------------
# PROMPTS flujos guiados para el agente
# ---------------------------------------------------------------------------
@mcp.prompt(
name="triaje_inteligente",
description=(
"Plantilla para que el agente haga triaje de tickets abiertos: "
"los lista, identifica los más críticos, y sugiere reasignación de prioridad."
),
)
def prompt_triaje() -> str:
return (
"Realiza triaje inteligente de los tickets de soporte abiertos.\n\n"
"Pasos:\n"
"1. Llama a 'resumen_tickets_abiertos' para tener panorama\n"
"2. Lee tickets://by-estado/abierto para ver detalles\n"
"3. Identifica tickets que merecen escalado de prioridad por:\n"
" - Múltiples menciones de impacto a producción\n"
" - Clientes con múltiples tickets abiertos\n"
" - Términos críticos: 'caído', 'pérdida de datos', 'urgente'\n"
"4. Sugiere reasignaciones específicas usando 'actualizar_estado_ticket'\n"
"5. NO ejecutes los cambios automáticamente; solo sugiérelos\n"
)
# ---------------------------------------------------------------------------
# Lifecycle hooks
# ---------------------------------------------------------------------------
async def cleanup() -> None:
"""Cierra el cliente HTTP al apagar el servidor."""
await client.close()
# ---------------------------------------------------------------------------
# Punto de entrada
# ---------------------------------------------------------------------------
if __name__ == "__main__":
import atexit
import asyncio
atexit.register(lambda: asyncio.run(cleanup()))
log.info("server_starting", name="tickets-adapter",
api_url=client._client.base_url, transport="stdio")
mcp.run(transport="stdio")Qué está pasando aquí:
Este es el código que distingue un servidor MCP de juguete de uno de producción. Punto por punto:
Tools async de verdad. async def tool_crear_ticket(...). FastMCP 3 soporta async nativo. Cada llamada al backend no bloquea el event loop esencial cuando el servidor atiende múltiples requests concurrentes.
Validación en el borde MCP. El pattern=r"^CLI-\d{4}$" valida el formato del cliente_id antes de tocar la API. El LLM puede alucinar formatos yo no le dejo que la API tenga que limpiar su mugre.
Mapeo limpio de errores. TicketNotFound → ValueError("Ticket X no existe"). El agente recibe mensajes legibles, no stack traces. La capa de error de la API queda contenida en la capa de cliente HTTP.
Resources con fallback. En resource_obtener_ticket, si el ticket no existe devuelvo un dict con error en lugar de explotar. Los Resources se exponen como datos; un 404 no debería tirar el agente.
Prompts con instrucciones explícitas sobre human-in-the-loop. Mira el prompt_triaje: termina con "NO ejecutes los cambios automáticamente; solo sugiérelos". Eso es seguridad operacional embebida en el prompt el agente sugiere, el humano aprueba.
Cleanup del cliente HTTP. El atexit.register con cleanup() cierra el cliente HTTP al apagar el servidor. Sin esto, dejas conexiones colgadas.
7. Probar el servidor 2 contra la API real
Aquí necesitamos dos terminales simultáneas porque hay dos procesos.
Terminal 1 Levantar el backend:
bash
uv run uvicorn ejemplo_2_tickets.backend.api:app --port 8080 --reloadVerifica que responde:
bash
curl http://localhost:8080/health
# {"status":"ok"}Terminal 2 Levantar el servidor MCP con Inspector:
bash
uv run fastmcp dev ejemplo_2_tickets/mcp_server/server.pyAbre el Inspector en el navegador.
Flujo de prueba end-to-end:
Tool
resumen_tickets_abiertos→ "Run Tool" → devuelve el conteo por prioridad de los 2 tickets seed.Tool
crear_ticket_soportecon:titulo: "Lentitud en módulo de facturación"descripcion: "Los reportes tardan 30s en cargar desde esta mañana"cliente_id: "CLI-0123"prioridad: "alta"
Te devuelve el
Ticketcon suidgenerado (TKT-XXXXXXXX). Copia ese ID.Resource
tickets://detail/{ese_id}→ "Read" → ves el ticket completo.Tool
actualizar_estado_ticketcon:ticket_id: el que copiastenuevo_estado: "en_progreso"
Devuelve el ticket actualizado con
actualizado_encambiado.Resource
tickets://by-estado/abierto→ ahora ya no aparece ese ticket, porque pasó aen_progreso.
Qué está pasando aquí:
Acabas de hacer un flujo CRUD completo a través de MCP, contra una API REST real, con autenticación Bearer, validación Pydantic en ambos lados, y manejo de errores async.
Si vienes del mundo del tool calling tradicional, fíjate en lo que no tuviste que hacer: no escribiste el handler de JSON, no parseaste el tool_call del LLM, no manejaste la serialización del resultado. FastMCP hizo todo eso. Tú solo escribiste lógica.
8. Conectar ambos servidores a Claude Desktop
Aquí cierra el círculo: conectar los servidores a un agente real.
Edita el archivo de configuración de Claude Desktop:
macOS:
~/Library/Application Support/Claude/claude_desktop_config.jsonWindows:
%APPDATA%\Claude\claude_desktop_config.json
json
{
"mcpServers": {
"log-analyzer": {
"command": "uv",
"args": [
"--directory",
"/ruta/absoluta/a/mcp-servers-tutorial",
"run",
"python",
"-m",
"ejemplo_1_logs.server"
]
},
"tickets-adapter": {
"command": "uv",
"args": [
"--directory",
"/ruta/absoluta/a/mcp-servers-tutorial",
"run",
"python",
"-m",
"ejemplo_2_tickets.mcp_server.server"
],
"env": {
"TICKETS_API_BASE_URL": "http://localhost:8080",
"TICKETS_API_TOKEN": "dev-token-no-prod"
}
}
}
}Reinicia Claude Desktop. En la UI verás el icono de herramientas MCP ambos servidores conectados.
Ahora pruébale al agente:
"Analiza los logs de mi aplicación y dime si hay algún patrón de errores preocupante."
El agente va a usar el prompt_analizar_incidente, las tools y los resources del servidor log-analyzer. Sin que le digas qué tool usar él decide basándose en las descripciones.
O bien:
"Crea un ticket de prioridad alta para el cliente CLI-0042: el módulo de reportes está caído desde hace 20 minutos."
El agente parsea, valida el formato del cliente, llama a crear_ticket_soporte, recibe el ID, te lo confirma.
9. Patrones de producción que aplicamos
Mira atrás. Lo que construimos hoy aplica los patrones que yo uso en proyectos enterprise reales:
Patrón | Dónde lo aplicamos |
|---|---|
Configuración por env vars con validación |
|
Separación servidor / servicios |
|
Modelos Pydantic en todos los bordes | Inputs, outputs, payloads de API |
Excepciones de dominio propias |
|
Defensa en profundidad | Validación de path traversal en 2 niveles |
Async donde corresponde | Tools async en el adaptador de API |
Secretos protegidos |
|
Logging estructurado |
|
Cleanup explícito |
|
Prompts con human-in-the-loop |
|
Ninguno de estos patrones es opcional cuando estás en producción real. Son la diferencia entre un servidor MCP que funciona en una demo y uno que aguanta tráfico real con observabilidad y seguridad.
Una capa vs dos capas la decisión final
Después de ver los dos ejemplos, la decisión arquitectónica debería ser obvia:
Usa una capa cuando:
La fuente de datos es local (filesystem, SQLite embebido, archivos de config)
No hay API previa ni lógica de negocio compartida con otros sistemas
Las herramientas son específicas para un agente concreto
Estás construyendo developer tools o utilities personales
Usa dos capas cuando:
Ya existe una API REST que otros sistemas también consumen
Hay lógica de negocio centralizada que no quieres duplicar
Necesitas que la IA sea un consumer más del sistema, no un caso especial
Hay requisitos de auditoría, autenticación o compliance que viven en la API
La arquitectura de dos capas no es complejidad gratuita. Es la única forma de incorporar IA a un sistema enterprise sin contaminarlo.
10. Lo que sigue en la serie MCP
Cerramos esta entrega de la serie con dos servidores que realmente funcionan y que puedes adaptar a tu propio caso. El código completo, sin atajos.
Lo que viene en próximos posts de la serie:
RAG en profundidad: lo prometí en el post anterior y va. Construcción de un sistema RAG de calidad de producción con vectorial store, búsqueda híbrida y reranking. Más adelante un híbrido con MCP RAG sirviendo conocimiento, MCP ejecutando acciones.
A2A comunicación entre agentes: el otro protocolo que mencioné en el post teórico. Cómo coordinar múltiples agentes con Agent Cards y delegar tareas entre ellos.
MCP en producción con Streamable HTTP y OAuth 2.1: lo de hoy fue stdio. El siguiente nivel es desplegar tu servidor MCP en cloud, con transport HTTP, autenticación OAuth y observabilidad con OpenTelemetry. El stack completo de producción.
Si llegaste hasta aquí, ya no estás construyendo "un servidor MCP". Estás construyendo arquitectura de IA empresarial con MCP como protocolo. Hay diferencia.
Construye con criterio.
#MCP #FastMCP #ModelContextProtocol #Python #AgenticAI #AIArchitecture #LLMOps #SoftwareEngineering #DataScience #AIEngineering